Business Problem¶
Business Problem:
Task : Detect the fraudulent activities.
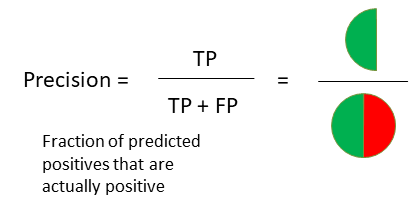
Metric : Recall
Sampling: Synthetic Minority Over-Sampling Technique (SMOTE)
Question: How many frauds are correctly classified?
Remember that Recall = TP / (TP + FN). In case of fraud detection,
classifying a fraud as
non-fraud (FN) is more risky so we use the metric recall to compare the
performances of the models. Higher the recall, better is the model.
The dataset is highly imbalanced. It has 284k non-frauds and 1k frauds.
This means out of 1000 transatiosn, 998 are normal and 2 are fraud cases.
Also, we should note that the data is just of two days, we implicitly assume that
these two days are represent of the whole trend and reflects the property
of the population properly.
The could have been more or less fraudulent transactions in those particular days,
but we would not take that into consideration and we generalizes the result.
Or, we can say that based on the data from these two days we reached following
conclusion and the result is appropriate for the population where the data
distribution is similar to that of these two days.
We are more interestd in finding the Fraud cases. i.e. FN (False Negative) cases,
predicting fraud as non-fraud is riskier than predicting non-fraud as fraud.
So, the suitable metric of model evaluation is RECALL.
In banking, it is always the case that there are a lot of normal transactions,
and only few of them are fraudulent. We may train our model with any transformation
of the training data, but when testing the model the test set should look like
real life, i.e., it has lots of normal cases and very few fraudulent cases.
This means we can train our model using imbalanced or balanced (undersamples
or oversampled) but we should test our model on IMBALANCED dataset.
WARNINGS for Serialization:
When using the picked object (serialized object),
the machine should have all the same versions of libraries used, such as numpy,
pandas, scikit-learn, and all other dependency libraries.
So, to load the serialized object make sure you have the
same conda environment as it was when creating the serialized object.
NOTE: When using Logistic Regression for classification problems,
we have different solvers in scikit-learn such as `liblinear`, `lbfgs`,
`sag`, `saga` and `newton-cg`.
`liblinear` only supports `l1` and `l2` penalty. and `saga` only supports
`elasticnet`.
For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ and ‘saga’ are faster for large ones.
For multiclass problems, only ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ handle multinomial loss; ‘liblinear’ is limited to one-versus-rest schemes.
‘newton-cg’, ‘lbfgs’, ‘sag’ and ‘saga’ handle L2 or no penalty
‘liblinear’ and ‘saga’ also handle L1 penalty
‘saga’ also supports ‘elasticnet’ penalty
‘liblinear’ does not handle no penalty.
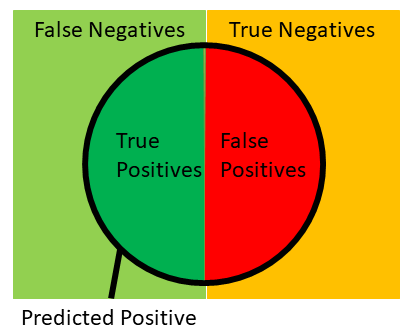
NOTE: Confusion Matrix Terms
Fraud ==> Fraud TP
Non-Fraud ==> Non-Fraud TN
Fraud ==> Non-Fraud FN (I am interested in this)
Non-Fraud ==> Fraud FP