Data Description¶
This dataset contains house sale prices for King County, which includes Seattle. It includes homes sold between May 2014 and May 2015.
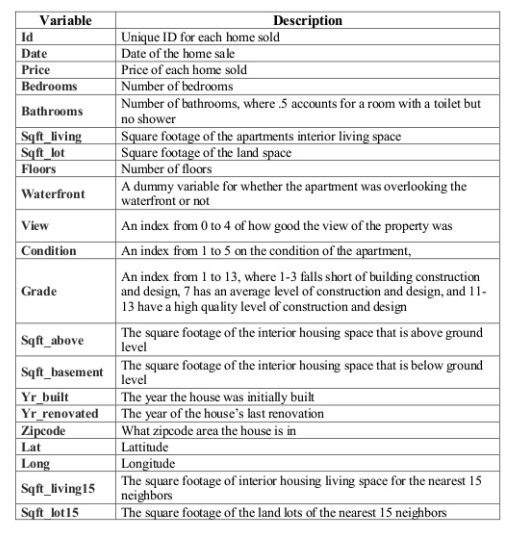
This dataset contains house sale prices for King County, which includes Seattle. It includes homes sold between May 2014 and May 2015.
import time
time_start_notebook = time.time()
# my local library
import sys
sys.path.append("/Users/poudel/Dropbox/a00_Bhishan_Modules/")
sys.path.append("/Users/poudel/Dropbox/a00_Bhishan_Modules/bhishan")
from bhishan import bp
/Users/poudel/opt/miniconda3/envs/dataSc/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject /Users/poudel/opt/miniconda3/envs/dataSc/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject /Users/poudel/opt/miniconda3/envs/dataSc/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject /Users/poudel/opt/miniconda3/envs/dataSc/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject /Users/poudel/opt/miniconda3/envs/dataSc/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
# usual imports
import numpy as np
import pandas as pd
# mixed
import os
import time
# random state
RNG = np.random.RandomState(0)
# versions
import watermark
%load_ext watermark
%watermark -a "Bhishan Poudel" -d -v -m
print()
%watermark -iv
/Users/poudel/opt/miniconda3/envs/dataSc/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
--------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) <ipython-input-1-9740b3cc0240> in <module> 4 5 # local imports ----> 6 from bhishan import bp 7 8 # mixed ~/Dropbox/a00_Bhishan_Modules/bhishan/__init__.py in <module> 12 __version__ = '0.4.0' 13 ---> 14 from .pandas_api import BPAccessor 15 16 ~/Dropbox/a00_Bhishan_Modules/bhishan/pandas_api.py in <module> 58 59 # it was .plot_utils I changed only plot_utils ---> 60 from plot_utils import (add_text_barplot, magnify, 61 get_mpl_style, get_plotly_colorscale) 62 ModuleNotFoundError: No module named 'plot_utils'
%%javascript
IPython.OutputArea.auto_scroll_threshold = 9999;
def show_methods(method, ncols=7):
""" Show all the attributes of a given method.
Example:
========
show_method_attributes(list)
"""
x = [i for i in dir(method) if i[0].islower()]
return pd.DataFrame(np.array_split(x,ncols)).T.fillna('')
def json_dump_tofile(myjson,ofile,sort_keys=False):
"""Write json dictionary to a datafile.
Usage:
myjson = {'num': 5, my_list = [1,2,'apple']}
json_dump_tofile(myjson, ofile)
"""
import io
import json
with io.open(ofile, 'w', encoding='utf8') as fo:
json_str = json.dumps(myjson,
indent=4,
sort_keys=sort_keys,
separators=(',', ': '),
ensure_ascii=False)
fo.write(str(json_str))
df = pd.read_csv('../data/raw/kc_house_data.csv')
print(df.shape)
df.head().T
(21613, 21)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| id | 7129300520 | 6414100192 | 5631500400 | 2487200875 | 1954400510 |
| date | 20141013T000000 | 20141209T000000 | 20150225T000000 | 20141209T000000 | 20150218T000000 |
| price | 221900 | 538000 | 180000 | 604000 | 510000 |
| bedrooms | 3 | 3 | 2 | 4 | 3 |
| bathrooms | 1 | 2.25 | 1 | 3 | 2 |
| sqft_living | 1180 | 2570 | 770 | 1960 | 1680 |
| sqft_lot | 5650 | 7242 | 10000 | 5000 | 8080 |
| floors | 1 | 2 | 1 | 1 | 1 |
| waterfront | 0 | 0 | 0 | 0 | 0 |
| view | 0 | 0 | 0 | 0 | 0 |
| condition | 3 | 3 | 3 | 5 | 3 |
| grade | 7 | 7 | 6 | 7 | 8 |
| sqft_above | 1180 | 2170 | 770 | 1050 | 1680 |
| sqft_basement | 0 | 400 | 0 | 910 | 0 |
| yr_built | 1955 | 1951 | 1933 | 1965 | 1987 |
| yr_renovated | 0 | 1991 | 0 | 0 | 0 |
| zipcode | 98178 | 98125 | 98028 | 98136 | 98074 |
| lat | 47.5112 | 47.721 | 47.7379 | 47.5208 | 47.6168 |
| long | -122.257 | -122.319 | -122.233 | -122.393 | -122.045 |
| sqft_living15 | 1340 | 1690 | 2720 | 1360 | 1800 |
| sqft_lot15 | 5650 | 7639 | 8062 | 5000 | 7503 |
# bp.show_methods(bp)
bp.get_column_descriptions(df)
| column | dtype | nunique | nans | nans_pct | nzeros | nzeros_pct | |
|---|---|---|---|---|---|---|---|
| 0 | id | int64 | 21436 | 0 | 0.0% | 0 | 0.0% |
| 1 | date | object | 372 | 0 | 0.0% | 0 | 0.0% |
| 2 | price | float64 | 4028 | 0 | 0.0% | 0 | 0.0% |
| 3 | bedrooms | int64 | 13 | 0 | 0.0% | 13 | 0.06% |
| 4 | bathrooms | float64 | 30 | 0 | 0.0% | 10 | 0.05% |
| 5 | sqft_living | int64 | 1038 | 0 | 0.0% | 0 | 0.0% |
| 6 | sqft_lot | int64 | 9782 | 0 | 0.0% | 0 | 0.0% |
| 7 | floors | float64 | 6 | 0 | 0.0% | 0 | 0.0% |
| 8 | waterfront | int64 | 2 | 0 | 0.0% | 21450 | 99.25% |
| 9 | view | int64 | 5 | 0 | 0.0% | 19489 | 90.17% |
| 10 | condition | int64 | 5 | 0 | 0.0% | 0 | 0.0% |
| 11 | grade | int64 | 12 | 0 | 0.0% | 0 | 0.0% |
| 12 | sqft_above | int64 | 946 | 0 | 0.0% | 0 | 0.0% |
| 13 | sqft_basement | int64 | 306 | 0 | 0.0% | 13126 | 60.73% |
| 14 | yr_built | int64 | 116 | 0 | 0.0% | 0 | 0.0% |
| 15 | yr_renovated | int64 | 70 | 0 | 0.0% | 20699 | 95.77% |
| 16 | zipcode | int64 | 70 | 0 | 0.0% | 0 | 0.0% |
| 17 | lat | float64 | 5034 | 0 | 0.0% | 0 | 0.0% |
| 18 | long | float64 | 752 | 0 | 0.0% | 0 | 0.0% |
| 19 | sqft_living15 | int64 | 777 | 0 | 0.0% | 0 | 0.0% |
| 20 | sqft_lot15 | int64 | 8689 | 0 | 0.0% | 0 | 0.0% |
df['date'] = pd.to_datetime(df['date'])
df['date'].head(2)
0 2014-10-13 1 2014-12-09 Name: date, dtype: datetime64[ns]
df['yr_sales'] = df['date'].dt.year
df.head(2)
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | waterfront | view | ... | sqft_above | sqft_basement | yr_built | yr_renovated | zipcode | lat | long | sqft_living15 | sqft_lot15 | yr_sales | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7129300520 | 2014-10-13 | 221900.0 | 3 | 1.00 | 1180 | 5650 | 1.0 | 0 | 0 | ... | 1180 | 0 | 1955 | 0 | 98178 | 47.5112 | -122.257 | 1340 | 5650 | 2014 |
| 1 | 6414100192 | 2014-12-09 | 538000.0 | 3 | 2.25 | 2570 | 7242 | 2.0 | 0 | 0 | ... | 2170 | 400 | 1951 | 1991 | 98125 | 47.7210 | -122.319 | 1690 | 7639 | 2014 |
2 rows × 22 columns
df['age'] = df['yr_sales'] - df['yr_built']
df[['yr_sales','yr_built','age']].head(2)
| yr_sales | yr_built | age | |
|---|---|---|---|
| 0 | 2014 | 1955 | 59 |
| 1 | 2014 | 1951 | 63 |
df[df['age'] < 0] # some houses were sold before they are built.
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | waterfront | view | ... | sqft_basement | yr_built | yr_renovated | zipcode | lat | long | sqft_living15 | sqft_lot15 | yr_sales | age | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1763 | 1832100030 | 2014-06-25 | 597326.0 | 4 | 4.00 | 3570 | 8250 | 2.0 | 0 | 0 | ... | 710 | 2015 | 0 | 98040 | 47.5784 | -122.226 | 2230 | 10000 | 2014 | -1 |
| 2687 | 3076500830 | 2014-10-29 | 385195.0 | 1 | 1.00 | 710 | 6000 | 1.5 | 0 | 0 | ... | 0 | 2015 | 0 | 98144 | 47.5756 | -122.316 | 1440 | 4800 | 2014 | -1 |
| 7526 | 9520900210 | 2014-12-31 | 614285.0 | 5 | 2.75 | 2730 | 6401 | 2.0 | 0 | 0 | ... | 0 | 2015 | 0 | 98072 | 47.7685 | -122.160 | 2520 | 6126 | 2014 | -1 |
| 8039 | 1250200495 | 2014-06-24 | 455000.0 | 2 | 1.50 | 1200 | 1259 | 2.0 | 0 | 0 | ... | 200 | 2015 | 0 | 98144 | 47.6001 | -122.298 | 1320 | 1852 | 2014 | -1 |
| 14489 | 2770601530 | 2014-08-26 | 500000.0 | 2 | 2.25 | 1570 | 1269 | 2.0 | 0 | 0 | ... | 290 | 2015 | 0 | 98199 | 47.6514 | -122.385 | 1570 | 6000 | 2014 | -1 |
| 17098 | 9126100346 | 2014-06-17 | 350000.0 | 3 | 2.00 | 1380 | 3600 | 3.0 | 0 | 0 | ... | 0 | 2015 | 0 | 98122 | 47.6074 | -122.305 | 1480 | 3600 | 2014 | -1 |
| 19805 | 9126100765 | 2014-08-01 | 455000.0 | 3 | 1.75 | 1320 | 1014 | 3.0 | 0 | 0 | ... | 0 | 2015 | 0 | 98122 | 47.6047 | -122.305 | 1380 | 1495 | 2014 | -1 |
| 20770 | 9310300160 | 2014-08-28 | 357000.0 | 5 | 2.50 | 2990 | 9240 | 2.0 | 0 | 0 | ... | 0 | 2015 | 0 | 98133 | 47.7384 | -122.348 | 1970 | 18110 | 2014 | -1 |
| 20852 | 1257201420 | 2014-07-09 | 595000.0 | 4 | 3.25 | 3730 | 4560 | 2.0 | 0 | 0 | ... | 970 | 2015 | 0 | 98103 | 47.6725 | -122.330 | 1800 | 4560 | 2014 | -1 |
| 20963 | 6058600220 | 2014-07-31 | 230000.0 | 3 | 1.50 | 1040 | 1264 | 2.0 | 0 | 0 | ... | 140 | 2015 | 0 | 98144 | 47.5951 | -122.301 | 1350 | 3000 | 2014 | -1 |
| 21262 | 5694500840 | 2014-11-25 | 559000.0 | 2 | 3.00 | 1650 | 960 | 3.0 | 0 | 0 | ... | 300 | 2015 | 0 | 98103 | 47.6611 | -122.346 | 1650 | 3000 | 2014 | -1 |
| 21372 | 6169901185 | 2014-05-20 | 490000.0 | 5 | 3.50 | 4460 | 2975 | 3.0 | 0 | 2 | ... | 1180 | 2015 | 0 | 98119 | 47.6313 | -122.370 | 2490 | 4231 | 2014 | -1 |
12 rows × 23 columns
df['yr_renovated2'] = np.where(df['yr_renovated'].eq(0), df['yr_built'], df['yr_renovated'])
df.filter(regex='yr',axis=1).head(2)
| yr_built | yr_renovated | yr_sales | yr_renovated2 | |
|---|---|---|---|---|
| 0 | 1955 | 0 | 2014 | 1955 |
| 1 | 1951 | 1991 | 2014 | 1991 |
df.filter(regex='yr_*',axis=1).loc[lambda x: x['yr_renovated'] !=0].head(2)
| yr_built | yr_renovated | yr_sales | yr_renovated2 | |
|---|---|---|---|---|
| 1 | 1951 | 1991 | 2014 | 1991 |
| 35 | 1930 | 2002 | 2014 | 2002 |
df['age_after_renovation'] = df['yr_sales'] - df['yr_renovated2']
df.filter(regex='yr|age',axis=1).head(2)
| yr_built | yr_renovated | yr_sales | age | yr_renovated2 | age_after_renovation | |
|---|---|---|---|---|---|---|
| 0 | 1955 | 0 | 2014 | 59 | 1955 | 59 |
| 1 | 1951 | 1991 | 2014 | 63 | 1991 | 23 |
df.filter(regex='yr|age',axis=1).loc[lambda x: x['yr_renovated'] !=0].head(2)
| yr_built | yr_renovated | yr_sales | age | yr_renovated2 | age_after_renovation | |
|---|---|---|---|---|---|---|
| 1 | 1951 | 1991 | 2014 | 63 | 1991 | 23 |
| 35 | 1930 | 2002 | 2014 | 84 | 2002 | 12 |
Ref: https://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html
df.head(1).append(df.dtypes,ignore_index=True)
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | waterfront | view | ... | yr_renovated | zipcode | lat | long | sqft_living15 | sqft_lot15 | yr_sales | age | yr_renovated2 | age_after_renovation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7129300520 | 2014-10-13 00:00:00 | 221900 | 3 | 1 | 1180 | 5650 | 1 | 0 | 0 | ... | 0 | 98178 | 47.5112 | -122.257 | 1340 | 5650 | 2014 | 59 | 1955 | 59 |
| 1 | int64 | datetime64[ns] | float64 | int64 | float64 | int64 | int64 | float64 | int64 | int64 | ... | int64 | int64 | float64 | float64 | int64 | int64 | int64 | int64 | int64 | int64 |
2 rows × 25 columns
cols_str = ['waterfront', 'view', 'condition', 'grade','zipcode']
for c in cols_str:
df[c] = df[c].astype(str)
cols_obj = df.select_dtypes(['object','category']).columns
cols_obj
Index(['waterfront', 'view', 'condition', 'grade', 'zipcode'], dtype='object')
df.select_dtypes(['object','category']).apply(pd.Series.nunique)
waterfront 2 view 5 condition 5 grade 12 zipcode 70 dtype: int64
cols_obj_small = ['waterfront', 'view', 'condition', 'grade']
for c in cols_obj_small:
print('\n=========================================')
print(c)
print(df[c].value_counts())
========================================= waterfront 0 21450 1 163 Name: waterfront, dtype: int64 ========================================= view 0 19489 2 963 3 510 1 332 4 319 Name: view, dtype: int64 ========================================= condition 3 14031 4 5679 5 1701 2 172 1 30 Name: condition, dtype: int64 ========================================= grade 7 8981 8 6068 9 2615 6 2038 10 1134 11 399 5 242 12 90 4 29 13 13 3 3 1 1 Name: grade, dtype: int64
with pd.option_context('display.max_colwidth', 500):
display(df.select_dtypes(['object','category']).apply(
lambda x: str(pd.Series.unique(x).tolist()) ).to_frame())
| 0 | |
|---|---|
| waterfront | ['0', '1'] |
| view | ['0', '3', '4', '2', '1'] |
| condition | ['3', '5', '4', '1', '2'] |
| grade | ['7', '6', '8', '11', '9', '5', '10', '12', '4', '3', '13', '1'] |
| zipcode | ['98178', '98125', '98028', '98136', '98074', '98053', '98003', '98198', '98146', '98038', '98007', '98115', '98107', '98126', '98019', '98103', '98002', '98133', '98040', '98092', '98030', '98119', '98112', '98052', '98027', '98117', '98058', '98001', '98056', '98166', '98023', '98070', '98148', '98105', '98042', '98008', '98059', '98122', '98144', '98004', '98005', '98034', '98075', '98116', '98010', '98118', '98199', '98032', '98045', '98102', '98077', '98108', '98168', '98177', '98065', ... |
df['zipcode'].value_counts().head()
98103 602 98038 590 98115 583 98052 574 98117 553 Name: zipcode, dtype: int64
df['zipcode'].value_counts().hist()
<matplotlib.axes._subplots.AxesSubplot at 0x7fc172589990>

# zipcode is related to house price, we may not want to drop it.
# there are 70 unique zipcode values, it will create too many dummies.
# one choice is taking top 5 or top 10 zipcodes
# we can choose top 10 zipcodes with largest house price.
# (or may be largest number of houses in that zipcode.)
# df[['zipcode','price']].sort_values('price').tail(20)
df[['zipcode','price']].sort_values(['price','zipcode']).drop_duplicates('zipcode',keep='last').tail(10)
| zipcode | price | |
|---|---|---|
| 2864 | 98144 | 3600000.0 |
| 6508 | 98105 | 3650000.0 |
| 19017 | 98177 | 3800000.0 |
| 12370 | 98006 | 4208000.0 |
| 2626 | 98155 | 4500000.0 |
| 1164 | 98033 | 5110800.0 |
| 1315 | 98040 | 5300000.0 |
| 9254 | 98039 | 6885000.0 |
| 3914 | 98004 | 7062500.0 |
| 7252 | 98102 | 7700000.0 |
most_expensive9_zipcodes = (df[['zipcode','price']]
.sort_values(['price','zipcode'])
.drop_duplicates('zipcode',keep='last')
.tail(9)
.zipcode
.values
)
most_expensive9_zipcodes
array(['98105', '98177', '98006', '98155', '98033', '98040', '98039',
'98004', '98102'], dtype=object)
# keep same zipcode for top 9 expensive and make all others as others
df['zipcode_top10'] = df['zipcode']
df.loc[~df['zipcode_top10'].isin(most_expensive9_zipcodes), 'zipcode_top10'] = 'others'
# we can also create new feature number of houses in that zipcode
df['zipcode_houses'] = df.groupby(['zipcode'])['price'].transform('count')
df.filter(regex='zip|price',axis=1).drop_duplicates('zipcode_top10')
| price | zipcode | zipcode_top10 | zipcode_houses | |
|---|---|---|---|---|
| 0 | 221900.0 | 98178 | others | 262 |
| 21 | 2000000.0 | 98040 | 98040 | 282 |
| 54 | 920000.0 | 98105 | 98105 | 229 |
| 66 | 975000.0 | 98004 | 98004 | 317 |
| 100 | 850830.0 | 98102 | 98102 | 105 |
| 120 | 660000.0 | 98177 | 98177 | 255 |
| 141 | 527700.0 | 98006 | 98006 | 498 |
| 173 | 917500.0 | 98033 | 98033 | 432 |
| 194 | 230000.0 | 98155 | 98155 | 446 |
| 2974 | 2950000.0 | 98039 | 98039 | 50 |
cols_obj = df.select_dtypes(['object','category']).columns
cols_obj
Index(['waterfront', 'view', 'condition', 'grade', 'zipcode', 'zipcode_top10'], dtype='object')
# create ordered ordinal labels for categorical data
# waterfron, view, condition, grade are already ordered ordinals
df['zipcode'].nunique()
70
# create new column with rare 1% values named as rare for zipcode
df['zipcode'].head()
0 98178 1 98125 2 98028 3 98136 4 98074 Name: zipcode, dtype: object
# more frequent than 1%
zipcode_idx_greater_than_1pct = df['zipcode'].value_counts(normalize=True).loc[lambda x: x>0.01].index
zipcode_idx_greater_than_1pct
# 98045 0.01
# 98002 0.0092 # this index is Rare
Index(['98103', '98038', '98115', '98052', '98117', '98042', '98034', '98118',
'98023', '98006', '98133', '98059', '98058', '98155', '98074', '98033',
'98027', '98125', '98056', '98053', '98001', '98075', '98126', '98092',
'98144', '98106', '98116', '98029', '98199', '98004', '98065', '98122',
'98146', '98028', '98008', '98040', '98003', '98198', '98031', '98072',
'98112', '98168', '98055', '98107', '98136', '98178', '98030', '98177',
'98166', '98022', '98105', '98045'],
dtype='object')
df['zipcode_with_1pct_rare'] = np.where(df['zipcode'].isin(zipcode_idx_greater_than_1pct),
df['zipcode'], 'Rare')
print(df['zipcode_with_1pct_rare'].nunique())
df['zipcode_with_1pct_rare'].unique()
53
array(['98178', '98125', '98028', '98136', '98074', '98053', '98003',
'98198', '98146', '98038', 'Rare', '98115', '98107', '98126',
'98103', '98133', '98040', '98092', '98030', '98112', '98052',
'98027', '98117', '98058', '98001', '98056', '98166', '98023',
'98105', '98042', '98008', '98059', '98122', '98144', '98004',
'98034', '98075', '98116', '98118', '98199', '98045', '98168',
'98177', '98065', '98029', '98006', '98022', '98033', '98155',
'98031', '98106', '98072', '98055'], dtype=object)
var = 'zipcode_with_1pct_rare'
target = 'price'
zipcode_ordered_labels = df[[var,target]].groupby([var])[target].mean().sort_values().index
zipcode_ordinal_labels_dict = {k:i for i, k in enumerate(zipcode_ordered_labels, 0)}
zipcode_ordinal_labels_dict
{'98168': 0,
'98001': 1,
'98023': 2,
'98003': 3,
'98030': 4,
'98031': 5,
'98198': 6,
'98055': 7,
'98178': 8,
'98042': 9,
'98022': 10,
'98106': 11,
'98092': 12,
'98058': 13,
'98146': 14,
'98038': 15,
'98133': 16,
'98118': 17,
'98056': 18,
'98155': 19,
'98126': 20,
'98045': 21,
'98028': 22,
'98166': 23,
'98125': 24,
'98059': 25,
'98034': 26,
'98065': 27,
'98136': 28,
'Rare': 29,
'98072': 30,
'98117': 31,
'98107': 32,
'98103': 33,
'98144': 34,
'98029': 35,
'98027': 36,
'98116': 37,
'98115': 38,
'98122': 39,
'98052': 40,
'98008': 41,
'98177': 42,
'98053': 43,
'98074': 44,
'98075': 45,
'98199': 46,
'98033': 47,
'98006': 48,
'98105': 49,
'98112': 50,
'98040': 51,
'98004': 52}
myjson = {'zipcode_ordinal_labels_dict': zipcode_ordinal_labels_dict}
ofile = '../models/zipcode_ordinal_labels_dict.json'
json_dump_tofile(myjson,ofile,sort_keys=False)
df['zipcode_with_1pct_rare_ordinal'] = df['zipcode_with_1pct_rare'].map(zipcode_ordinal_labels_dict)
df.filter(regex='price|zipcode').head()
| price | zipcode | zipcode_top10 | zipcode_houses | zipcode_with_1pct_rare | zipcode_with_1pct_rare_ordinal | |
|---|---|---|---|---|---|---|
| 0 | 221900.0 | 98178 | others | 262 | 98178 | 8 |
| 1 | 538000.0 | 98125 | others | 410 | 98125 | 24 |
| 2 | 180000.0 | 98028 | others | 283 | 98028 | 22 |
| 3 | 604000.0 | 98136 | others | 263 | 98136 | 28 |
| 4 | 510000.0 | 98074 | others | 441 | 98074 | 44 |
(df[[var,target]]
.groupby(var)
.agg({target: np.mean})
.sort_values(target)
.index
.to_frame()
.assign(rank= lambda dx: range(len(dx)))
.to_dict()
['rank']
)
{'98168': 0,
'98001': 1,
'98023': 2,
'98003': 3,
'98030': 4,
'98031': 5,
'98198': 6,
'98055': 7,
'98178': 8,
'98042': 9,
'98022': 10,
'98106': 11,
'98092': 12,
'98058': 13,
'98146': 14,
'98038': 15,
'98133': 16,
'98118': 17,
'98056': 18,
'98155': 19,
'98126': 20,
'98045': 21,
'98028': 22,
'98166': 23,
'98125': 24,
'98059': 25,
'98034': 26,
'98065': 27,
'98136': 28,
'Rare': 29,
'98072': 30,
'98117': 31,
'98107': 32,
'98103': 33,
'98144': 34,
'98029': 35,
'98027': 36,
'98116': 37,
'98115': 38,
'98122': 39,
'98052': 40,
'98008': 41,
'98177': 42,
'98053': 43,
'98074': 44,
'98075': 45,
'98199': 46,
'98033': 47,
'98006': 48,
'98105': 49,
'98112': 50,
'98040': 51,
'98004': 52}
df.head(1).append(df.dtypes,ignore_index=True)
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | waterfront | view | ... | sqft_living15 | sqft_lot15 | yr_sales | age | yr_renovated2 | age_after_renovation | zipcode_top10 | zipcode_houses | zipcode_with_1pct_rare | zipcode_with_1pct_rare_ordinal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7129300520 | 2014-10-13 00:00:00 | 221900 | 3 | 1 | 1180 | 5650 | 1 | 0 | 0 | ... | 1340 | 5650 | 2014 | 59 | 1955 | 59 | others | 262 | 98178 | 8 |
| 1 | int64 | datetime64[ns] | float64 | int64 | float64 | int64 | int64 | float64 | object | object | ... | int64 | int64 | int64 | int64 | int64 | int64 | object | int64 | object | int64 |
2 rows × 29 columns
df['sqft_basement'].value_counts().nlargest(5)
0 13126 600 221 700 218 500 214 800 206 Name: sqft_basement, dtype: int64
# there are so many zeros, we can create boolean column
# Note that there should not be nans here.
df['basement_bool'] = df['sqft_basement'].apply(lambda x: 1 if x>0 else 0)
df['renovation_bool'] = df['yr_renovated'].apply(lambda x: 1 if x>0 else 0)
df.filter(regex='base|reno',axis=1).head()
| sqft_basement | yr_renovated | yr_renovated2 | age_after_renovation | basement_bool | renovation_bool | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1955 | 59 | 0 | 0 |
| 1 | 400 | 1991 | 1991 | 23 | 1 | 1 |
| 2 | 0 | 0 | 1933 | 82 | 0 | 0 |
| 3 | 910 | 0 | 1965 | 49 | 1 | 0 |
| 4 | 0 | 0 | 1987 | 28 | 0 | 0 |
df.select_dtypes('number').head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| id | 7.129301e+09 | 6.414100e+09 | 5.631500e+09 | 2.487201e+09 | 1.954401e+09 |
| price | 2.219000e+05 | 5.380000e+05 | 1.800000e+05 | 6.040000e+05 | 5.100000e+05 |
| bedrooms | 3.000000e+00 | 3.000000e+00 | 2.000000e+00 | 4.000000e+00 | 3.000000e+00 |
| bathrooms | 1.000000e+00 | 2.250000e+00 | 1.000000e+00 | 3.000000e+00 | 2.000000e+00 |
| sqft_living | 1.180000e+03 | 2.570000e+03 | 7.700000e+02 | 1.960000e+03 | 1.680000e+03 |
| sqft_lot | 5.650000e+03 | 7.242000e+03 | 1.000000e+04 | 5.000000e+03 | 8.080000e+03 |
| floors | 1.000000e+00 | 2.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 |
| sqft_above | 1.180000e+03 | 2.170000e+03 | 7.700000e+02 | 1.050000e+03 | 1.680000e+03 |
| sqft_basement | 0.000000e+00 | 4.000000e+02 | 0.000000e+00 | 9.100000e+02 | 0.000000e+00 |
| yr_built | 1.955000e+03 | 1.951000e+03 | 1.933000e+03 | 1.965000e+03 | 1.987000e+03 |
| yr_renovated | 0.000000e+00 | 1.991000e+03 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 |
| lat | 4.751120e+01 | 4.772100e+01 | 4.773790e+01 | 4.752080e+01 | 4.761680e+01 |
| long | -1.222570e+02 | -1.223190e+02 | -1.222330e+02 | -1.223930e+02 | -1.220450e+02 |
| sqft_living15 | 1.340000e+03 | 1.690000e+03 | 2.720000e+03 | 1.360000e+03 | 1.800000e+03 |
| sqft_lot15 | 5.650000e+03 | 7.639000e+03 | 8.062000e+03 | 5.000000e+03 | 7.503000e+03 |
| yr_sales | 2.014000e+03 | 2.014000e+03 | 2.015000e+03 | 2.014000e+03 | 2.015000e+03 |
| age | 5.900000e+01 | 6.300000e+01 | 8.200000e+01 | 4.900000e+01 | 2.800000e+01 |
| yr_renovated2 | 1.955000e+03 | 1.991000e+03 | 1.933000e+03 | 1.965000e+03 | 1.987000e+03 |
| age_after_renovation | 5.900000e+01 | 2.300000e+01 | 8.200000e+01 | 4.900000e+01 | 2.800000e+01 |
| zipcode_houses | 2.620000e+02 | 4.100000e+02 | 2.830000e+02 | 2.630000e+02 | 4.410000e+02 |
| zipcode_with_1pct_rare_ordinal | 8.000000e+00 | 2.400000e+01 | 2.200000e+01 | 2.800000e+01 | 4.400000e+01 |
| basement_bool | 0.000000e+00 | 1.000000e+00 | 0.000000e+00 | 1.000000e+00 | 0.000000e+00 |
| renovation_bool | 0.000000e+00 | 1.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 |
df.head(1).append(df.dtypes,ignore_index=True)
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | waterfront | view | ... | yr_sales | age | yr_renovated2 | age_after_renovation | zipcode_top10 | zipcode_houses | zipcode_with_1pct_rare | zipcode_with_1pct_rare_ordinal | basement_bool | renovation_bool | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7129300520 | 2014-10-13 00:00:00 | 221900 | 3 | 1 | 1180 | 5650 | 1 | 0 | 0 | ... | 2014 | 59 | 1955 | 59 | others | 262 | 98178 | 8 | 0 | 0 |
| 1 | int64 | datetime64[ns] | float64 | int64 | float64 | int64 | int64 | float64 | object | object | ... | int64 | int64 | int64 | int64 | object | int64 | object | int64 | int64 | int64 |
2 rows × 31 columns
cols_bin = ['age','age_after_renovation']
df['age'].hist()
<matplotlib.axes._subplots.AxesSubplot at 0x7fc1753a4250>

df['age'].describe()
count 21613.000000 mean 43.317818 std 29.375493 min -1.000000 25% 18.000000 50% 40.000000 75% 63.000000 max 115.000000 Name: age, dtype: float64
df['age_cat'] = pd.cut(df['age'], 10, labels=range(10)).astype(str)
df['age_after_renovation_cat'] = pd.cut(df['age_after_renovation'], 10, labels=range(10))
cols_obj_cat = df.select_dtypes(include=[np.object, 'category']).columns
cols_obj_cat
Index(['waterfront', 'view', 'condition', 'grade', 'zipcode', 'zipcode_top10',
'zipcode_with_1pct_rare', 'age_cat', 'age_after_renovation_cat'],
dtype='object')
df.select_dtypes(include=['object','category']).head()
| waterfront | view | condition | grade | zipcode | zipcode_top10 | zipcode_with_1pct_rare | age_cat | age_after_renovation_cat | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 3 | 7 | 98178 | others | 98178 | 5 | 5 |
| 1 | 0 | 0 | 3 | 7 | 98125 | others | 98125 | 5 | 2 |
| 2 | 0 | 0 | 3 | 6 | 98028 | others | 98028 | 7 | 7 |
| 3 | 0 | 0 | 5 | 7 | 98136 | others | 98136 | 4 | 4 |
| 4 | 0 | 0 | 3 | 8 | 98074 | others | 98074 | 2 | 2 |
cols_dummy = ['waterfront', 'view', 'condition', 'grade', 'zipcode_top10',
'age_cat', 'age_after_renovation_cat']
df_dummy = pd.get_dummies(df[cols_dummy],drop_first=False)
df_dummy.head(2)
| waterfront_0 | waterfront_1 | view_0 | view_1 | view_2 | view_3 | view_4 | condition_1 | condition_2 | condition_3 | ... | age_after_renovation_cat_0 | age_after_renovation_cat_1 | age_after_renovation_cat_2 | age_after_renovation_cat_3 | age_after_renovation_cat_4 | age_after_renovation_cat_5 | age_after_renovation_cat_6 | age_after_renovation_cat_7 | age_after_renovation_cat_8 | age_after_renovation_cat_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
2 rows × 54 columns
print(df.shape)
df.head(2)
(21613, 33)
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | waterfront | view | ... | yr_renovated2 | age_after_renovation | zipcode_top10 | zipcode_houses | zipcode_with_1pct_rare | zipcode_with_1pct_rare_ordinal | basement_bool | renovation_bool | age_cat | age_after_renovation_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7129300520 | 2014-10-13 | 221900.0 | 3 | 1.00 | 1180 | 5650 | 1.0 | 0 | 0 | ... | 1955 | 59 | others | 262 | 98178 | 8 | 0 | 0 | 5 | 5 |
| 1 | 6414100192 | 2014-12-09 | 538000.0 | 3 | 2.25 | 2570 | 7242 | 2.0 | 0 | 0 | ... | 1991 | 23 | others | 410 | 98125 | 24 | 1 | 1 | 5 | 2 |
2 rows × 33 columns
df_encoded = pd.concat([df,df_dummy], axis=1)
print(df.shape)
df.head(2)
(21613, 33)
| id | date | price | bedrooms | bathrooms | sqft_living | sqft_lot | floors | waterfront | view | ... | yr_renovated2 | age_after_renovation | zipcode_top10 | zipcode_houses | zipcode_with_1pct_rare | zipcode_with_1pct_rare_ordinal | basement_bool | renovation_bool | age_cat | age_after_renovation_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7129300520 | 2014-10-13 | 221900.0 | 3 | 1.00 | 1180 | 5650 | 1.0 | 0 | 0 | ... | 1955 | 59 | others | 262 | 98178 | 8 | 0 | 0 | 5 | 5 |
| 1 | 6414100192 | 2014-12-09 | 538000.0 | 3 | 2.25 | 2570 | 7242 | 2.0 | 0 | 0 | ... | 1991 | 23 | others | 410 | 98125 | 24 | 1 | 1 | 5 | 2 |
2 rows × 33 columns
Log transformations make the features more Gaussian-like and linear models may give better performance.
bedrooms, bathrooms, floors, waterfront, view, condition, grade are categorical columns but we can also use them as numerical columns to see how to model performs.
lat and long are geo coordinates, they are also categorical and sometimes treated as numerical data.
basement = living - above is redundant variable, may be used or not. This is just a choice of feature engineering.
year columns can be converted to age columns and ages can be binned, however, they also can be treated as number and used in the model.
features with large values can be log1p transformed.
cols_log = ['price', 'sqft_living', 'sqft_lot', 'sqft_above',
'sqft_basement', 'sqft_living15', 'sqft_lot15']
for col in cols_log:
df['log1p_' + col] = np.log1p(df[col])
df_encoded['log1p_' + col] = np.log1p(df[col])
df.filter(regex='|'.join(cols_log)).head()
| price | sqft_living | sqft_lot | sqft_above | sqft_basement | sqft_living15 | sqft_lot15 | log1p_price | log1p_sqft_living | log1p_sqft_lot | log1p_sqft_above | log1p_sqft_basement | log1p_sqft_living15 | log1p_sqft_lot15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 221900.0 | 1180 | 5650 | 1180 | 0 | 1340 | 5650 | 12.309987 | 7.074117 | 8.639588 | 7.074117 | 0.000000 | 7.201171 | 8.639588 |
| 1 | 538000.0 | 2570 | 7242 | 2170 | 400 | 1690 | 7639 | 13.195616 | 7.852050 | 8.887791 | 7.682943 | 5.993961 | 7.433075 | 8.941153 |
| 2 | 180000.0 | 770 | 10000 | 770 | 0 | 2720 | 8062 | 12.100718 | 6.647688 | 9.210440 | 6.647688 | 0.000000 | 7.908755 | 8.995041 |
| 3 | 604000.0 | 1960 | 5000 | 1050 | 910 | 1360 | 5000 | 13.311331 | 7.581210 | 8.517393 | 6.957497 | 6.814543 | 7.215975 | 8.517393 |
| 4 | 510000.0 | 1680 | 8080 | 1680 | 0 | 1800 | 7503 | 13.142168 | 7.427144 | 8.997271 | 7.427144 | 0.000000 | 7.496097 | 8.923191 |
df.columns
Index(['id', 'date', 'price', 'bedrooms', 'bathrooms', 'sqft_living',
'sqft_lot', 'floors', 'waterfront', 'view', 'condition', 'grade',
'sqft_above', 'sqft_basement', 'yr_built', 'yr_renovated', 'zipcode',
'lat', 'long', 'sqft_living15', 'sqft_lot15', 'yr_sales', 'age',
'yr_renovated2', 'age_after_renovation', 'zipcode_top10',
'zipcode_houses', 'zipcode_with_1pct_rare',
'zipcode_with_1pct_rare_ordinal', 'basement_bool', 'renovation_bool',
'age_cat', 'age_after_renovation_cat', 'log1p_price',
'log1p_sqft_living', 'log1p_sqft_lot', 'log1p_sqft_above',
'log1p_sqft_basement', 'log1p_sqft_living15', 'log1p_sqft_lot15'],
dtype='object')
df.drop('id',inplace=True,axis=1)
df.isnull().sum().sum()
0
df_dummy.shape
(21613, 54)
df.to_csv('../data/processed/data_cleaned.csv',index=False,header=True)
df_encoded.to_csv('../data/processed/data_cleaned_encoded.csv',index=False,header=True)
df_encoded.columns
Index(['id', 'date', 'price', 'bedrooms', 'bathrooms', 'sqft_living',
'sqft_lot', 'floors', 'waterfront', 'view', 'condition', 'grade',
'sqft_above', 'sqft_basement', 'yr_built', 'yr_renovated', 'zipcode',
'lat', 'long', 'sqft_living15', 'sqft_lot15', 'yr_sales', 'age',
'yr_renovated2', 'age_after_renovation', 'zipcode_top10',
'zipcode_houses', 'zipcode_with_1pct_rare',
'zipcode_with_1pct_rare_ordinal', 'basement_bool', 'renovation_bool',
'age_cat', 'age_after_renovation_cat', 'waterfront_0', 'waterfront_1',
'view_0', 'view_1', 'view_2', 'view_3', 'view_4', 'condition_1',
'condition_2', 'condition_3', 'condition_4', 'condition_5', 'grade_1',
'grade_10', 'grade_11', 'grade_12', 'grade_13', 'grade_3', 'grade_4',
'grade_5', 'grade_6', 'grade_7', 'grade_8', 'grade_9',
'zipcode_top10_98004', 'zipcode_top10_98006', 'zipcode_top10_98033',
'zipcode_top10_98039', 'zipcode_top10_98040', 'zipcode_top10_98102',
'zipcode_top10_98105', 'zipcode_top10_98155', 'zipcode_top10_98177',
'zipcode_top10_others', 'age_cat_0', 'age_cat_1', 'age_cat_2',
'age_cat_3', 'age_cat_4', 'age_cat_5', 'age_cat_6', 'age_cat_7',
'age_cat_8', 'age_cat_9', 'age_after_renovation_cat_0',
'age_after_renovation_cat_1', 'age_after_renovation_cat_2',
'age_after_renovation_cat_3', 'age_after_renovation_cat_4',
'age_after_renovation_cat_5', 'age_after_renovation_cat_6',
'age_after_renovation_cat_7', 'age_after_renovation_cat_8',
'age_after_renovation_cat_9', 'log1p_price', 'log1p_sqft_living',
'log1p_sqft_lot', 'log1p_sqft_above', 'log1p_sqft_basement',
'log1p_sqft_living15', 'log1p_sqft_lot15'],
dtype='object')
time_taken = time.time() - time_start_notebook
h,m = divmod(time_taken,60*60)
print('Time taken to run whole notebook: {:.0f} hr '\
'{:.0f} min {:.0f} secs'.format(h, *divmod(m,60)))
Time taken to run whole notebook: 0 hr 0 min 7 secs