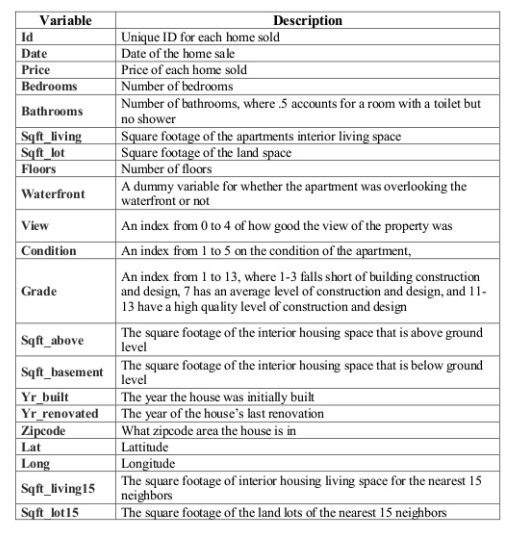
Data Description¶
This dataset contains house sale prices for King County, which includes Seattle. It includes homes sold between May 2014 and May 2015.
- Dependent features: 1 (price)
- Features : 19 home features
- Id: 1 house ID
Task: Estimate the price based on given features.