Kernel Author:
Bhishan Poudel, Ph.D Astrophysics .
Bhishan Poudel, Ph.D Astrophysics .
Data Description¶
In this project, we will predict the probability that an auto insurance policy holder files a claim. This a binary classification problem.
We have more than half a million records and 59 features (including already calculated features).
binary features: _bin
categorical features: _cat
continuous or ordinal feafures: ind, reg, car, calc
missing values: -1
Fullforms
ind = individual
reg = registration
car = car
calc = calculatedThe target columns signifies whether or not a claim was filed for that policy holder.
Evaluation Metric¶
- https://www.kaggle.com/c/porto-seguro-safe-driver-prediction/overview/evaluation
- https://en.wikipedia.org/wiki/Gini_coefficient
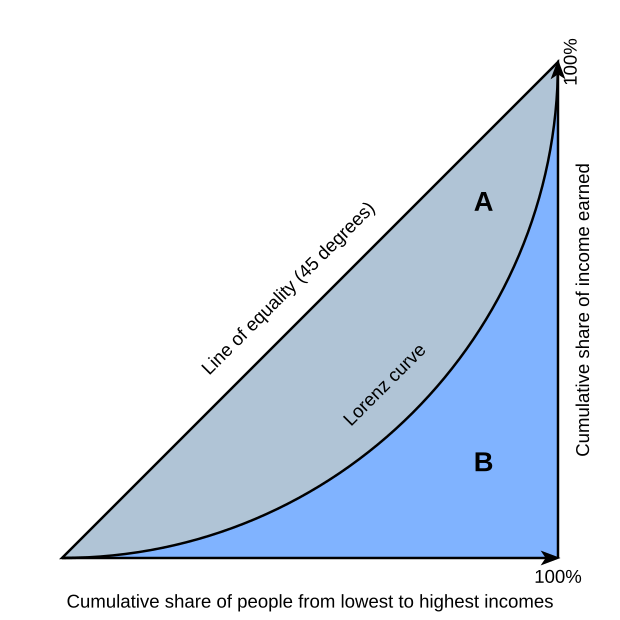
From this graph of wikipedia G = A / (A+B). Gini index varies between 0 and 1. Here we have only binary options: rich and poor.
x-axis= number of people (cumulative sum)
y-axis = total income (cumulative sum)
0 = complete equality of richness
1 = complete inequality of richness
This competition
0 = random guessing
1 = maximum score (also remember 2*1-1 = 1 when maximum auc is 1).If we calculate gini from gini = 2*auc -1 it has range (-1,1).
For AUC:
worst binary classifier AUC = 0.5
perfect binary classifier AUC = 1
If AUC is less than below, simply simply invert 0 <==> 1 then we will get roc auc score between 0.5 and 1.0Imports¶
In [1]:
import os
import time
import gc
import numpy as np
import pandas as pd
import scipy
from scipy import stats
import seaborn as sns
sns.set(color_codes=True)
import matplotlib
import matplotlib.pyplot as plt
from pprint import pprint
%matplotlib inline
time_start_notebook = time.time()
SEED=100
print([(x.__name__,x.__version__) for x in [np, pd,sns,matplotlib]])
In [2]:
from sklearn.model_selection import StratifiedKFold
In [3]:
# Google colab
In [4]:
%%capture
# capture will not print in notebook
import os
import sys
ENV_COLAB = 'google.colab' in sys.modules
if ENV_COLAB:
## mount google drive
from google.colab import drive
drive.mount('/content/drive')
## load the data dir
dat_dir = 'drive/My Drive/Colab Notebooks/data/'
sys.path.append(dat_dir)
## Image dir
img_dir = 'drive/My Drive/Colab Notebooks/images/'
if not os.path.isdir(img_dir): os.makedirs(img_dir)
sys.path.append(img_dir)
## Output dir
out_dir = 'drive/My Drive/Colab Notebooks/outputs/Porto/'
if not os.path.isdir(out_dir): os.makedirs(out_dir)
sys.path.append(out_dir)
# extra modules
# boruta shuffles the values within a column, and fits
# random forest (bagging) to make sure the score is
# not due to noise.
# https://github.com/scikit-learn-contrib/boruta_py
!pip install Boruta
#### print
print('Environment: Google Colaboratory.')
# NOTE: If we update modules in gcolab, we need to restart runtime.
In [4]:
Useful Functions¶
In [5]:
df_eval = pd.DataFrame({'Model': [],
'Description':[],
'Accuracy':[],
'Precision':[],
'Recall':[],
'F1':[],
'AUC':[],
'NormalizedGini': []
})
Load the data¶
In [6]:
df = pd.read_csv('https://github.com/bhishanpdl/Datasets/blob/master/'
'Porto_seguro_safe_driver_prediction/train.csv.zip?raw=true',compression='zip')
print(df.shape)
# faster runtime
# df = df.sample(frac=0.01,random_state=SEED)
df.head()
Out[6]:
In [7]:
target = 'target'
Train-test Split with Stratify¶
In [8]:
from sklearn.model_selection import train_test_split
df_Xtrain, df_Xtest, ser_ytrain, ser_ytest = train_test_split(
df.drop(target,axis=1),df[target],
test_size=0.2,random_state=SEED, stratify=df[target])
# backup and delete id
cols_drop = ['id']
train_id = df_Xtrain[cols_drop]
test_id = df_Xtest[cols_drop]
df_Xtrain = df_Xtrain.drop(cols_drop,axis=1)
df_Xtest = df_Xtest.drop(cols_drop,axis=1)
Xtrain = df_Xtrain.to_numpy()
ytrain = ser_ytrain.to_numpy().ravel()
Xtest = df_Xtest.to_numpy()
ytest = ser_ytest.to_numpy().ravel()
# make sure no nans and no strings
print(Xtrain.sum().sum())
Training Data¶
In [9]:
pd.set_option('display.max_columns',250)
df_Xtrain.head()
Out[9]:
In [10]:
# df_Xtrain.columns # make sure there are no id and index
In [11]:
Xtr = Xtrain
Xtx = Xtest
ytr = ytrain
ytx = ytest
print(Xtr.shape, Xtx.shape)
In [12]:
ser_ytest.value_counts(normalize=True)
Out[12]:
Evaluation Metric¶
In [13]:
def eval_gini(y_true, y_prob):
y_true = np.asarray(y_true)
y_true = y_true[np.argsort(y_prob)]
ntrue = 0
gini = 0
delta = 0
n = len(y_true)
for i in range(n-1, -1, -1):
y_i = y_true[i]
ntrue += y_i
gini += y_i * delta
delta += 1 - y_i
gini = 1 - 2 * gini / (ntrue * (n - ntrue))
return gini
In [14]:
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
import joblib
boruta_pkl = out_dir + 'porto_boruta.pkl'
print(boruta_pkl)
In [15]:
# we need to choose the good hyperparameters ourself
# eg. n_est = 100 and max_depth = 10 did not select enough features.
if not os.path.isfile(boruta_pkl):
rfc = RandomForestClassifier(n_estimators=200, n_jobs=-1,
class_weight='balanced', max_depth=6)
boruta_selector = BorutaPy(rfc, n_estimators='auto', verbose=2)
start_time = timer(None)
boruta_selector.fit(Xtrain, ytrain)
timer(start_time)
joblib.dump(boruta_selector, boruta_pkl)
else:
boruta_selector = joblib.load(boruta_pkl)
In [16]:
# number of selected features
print('Total :', df_Xtrain.shape[1])
print('Selected :', boruta_selector.n_features_)
print('Excluded :', df_Xtrain.shape[1] - boruta_selector.n_features_)
In [17]:
df_feat = pd.DataFrame({'feature': df_Xtrain.columns})
df_feat['rank'] = boruta_selector.ranking_
df_feat['support'] = boruta_selector.support_
df_feat['support_weak'] = boruta_selector.support_weak_
df_feat = df_feat.sort_values('rank',ascending=True).reset_index()
df_feat.head()
Out[17]:
In [18]:
cols_boruta_selected = selected =df_Xtrain.columns[boruta_selector.support_]
print(cols_boruta_selected)
In [19]:
from lightgbm import LGBMClassifier
from sklearn.model_selection import StratifiedKFold
In [20]:
clf = LGBMClassifier(num_leaves=1024,
max_depth=6,
n_estimators=500,
subsample=.632,
colsample_bytree=.5,
n_jobs=-1)
n_splits = 2
n_runs = 5
df_imp = np.zeros((len(df_Xtrain.columns), n_splits * n_runs))
idx = np.arange(len(ytrain))
time_start = time.time()
for run in range(n_runs):
# Shuffle target
np.random.seed(SEED)
np.random.shuffle(idx)
ser_perm_train = ser_ytrain.iloc[idx]
# Create a new split
folds = StratifiedKFold(n_splits, shuffle=True, random_state=SEED)
oof = np.empty(len(df_Xtrain))
for fold_, (idx_tr, idx_vd) in enumerate(
folds.split(ser_perm_train, ser_perm_train)):
print('Fold: ',fold_)
df_Xtr, ser_perm_tr = df_Xtrain.iloc[idx_tr], ser_perm_train.iloc[idx_tr]
df_Xvd, ser_perm_vd = df_Xtrain.iloc[idx_vd], ser_perm_train.iloc[idx_vd]
# Train classifier
clf.fit(df_Xtr, ser_perm_tr)
# Keep feature importances for this fold and run
df_imp[:, n_splits * run + fold_] = clf.feature_importances_
# Update OOF for gini score display
oof[idx_vd] = clf.predict_proba(df_Xvd)[:, 1]
# time taken
time_taken = time.time() - time_start
h,m = divmod(time_taken,60*60)
print(' Time taken : {:.0f} hr '\
'{:.0f} min {:.0f} secs\n'.format(h, *divmod(m,60)))
print("Run %2d OOF score (target shuffled) : %.6f" %
(run, eval_gini(ser_perm_train, oof)))
Shuffle target and data and compare¶
In [22]:
df_bench_imp = np.zeros((len(df_Xtrain.columns), n_splits * n_runs))
# default boosting_type = 'gbdt' but if we use rf
# we must give bagging_freq=1 and bagging_fraction < 1.0
# https://github.com/microsoft/LightGBM/issues/1333
clf = LGBMClassifier(num_leaves=1024,
max_depth=6,
n_estimators=500,
subsample=.632,
colsample_bytree=.5,
n_jobs=-1)
time_start = time.time()
for run in range(n_runs):
# Shuffle target AND dataset
np.random.seed(SEED)
np.random.shuffle(idx)
ser_perm_ytrain = ser_ytrain.iloc[idx]
df_perm_Xtrain = df_Xtrain.iloc[idx]
# Create a new split
folds = StratifiedKFold(n_splits, shuffle=True, random_state=SEED)
oof = np.empty(len(df_Xtrain))
for fold_, (idx_tr, idx_vd) in enumerate(
folds.split(ser_perm_ytrain, ser_perm_ytrain)):
print('Fold: ', fold_)
df_Xtr, ser_perm_ytr = df_perm_Xtrain.iloc[idx_tr], ser_perm_ytrain.iloc[idx_tr]
df_Xvd, ser_perm_yvd = df_perm_Xtrain.iloc[idx_vd], ser_perm_ytrain.iloc[idx_vd]
# Train classifier
clf.fit(df_Xtr, ser_perm_ytr)
# Keep feature importances for this fold and run
df_bench_imp[:, n_splits * run + fold_] = clf.feature_importances_
# Update OOF for gini score display
oof[idx_vd] = clf.predict_proba(df_Xvd)[:, 1]
# time taken
time_taken = time.time() - time_start
h,m = divmod(time_taken,60*60)
print(' Time taken : {:.0f} hr '\
'{:.0f} min {:.0f} secs\n'.format(h, *divmod(m,60)))
print("Run %2d OOF score (target+data shuffled): %.6f" %
(run, eval_gini(ser_perm_ytrain, oof)))
In [23]:
bench_mean = df_bench_imp.mean(axis=1)
perm_mean = df_imp.mean(axis=1)
df_compare = pd.DataFrame({'feature': df_Xtrain.columns,
'feat_imp_T_shuff': bench_mean,
'feat_imp_TD_shuff': perm_mean})
df_compare['ratio'] = (df_compare['feat_imp_T_shuff'] /
df_compare['feat_imp_TD_shuff'])
df_compare.sort_values('ratio',ascending=False).head()
Out[23]:
In [24]:
df_compare.sort_values('feat_imp_TD_shuff',ascending=False).head()
Out[24]:
In [25]:
df_compare.sort_values('feat_imp_TD_shuff',ascending=False).tail(10)
Out[25]:
In [26]:
df_compare.sort_values('feat_imp_T_shuff',ascending=False).tail(10)
Out[26]:
In [27]:
# not all of the bottom ones are calc features.
# note that in this dataset, they are useless but still the method
# failed to recongnize them.
#
# the tree methods looks for best combination to get the better score,
# that does not necessarily means it selects only the best features by default.
Time Taken¶
In [29]:
time_taken = time.time() - time_start_notebook
h,m = divmod(time_taken,60*60)
print('Time taken to run whole notebook: {:.0f} hr '\
'{:.0f} min {:.0f} secs'.format(h, *divmod(m,60)))
In [ ]: