N.B.
1. Collection of my projects since MS and PhD in Physics from 2014 about Python, SQL, AWS, Azure, PowerBI and Software Developments.
2. If the link does not expand when clicked, please scroll to the bottom of page for full view.
3. I have more than 17000 reputation and more than 5 million page visits in my StackOverflow page, please visit the link for more details.
4. With 10+ years of experience in data science, I have created my own DS library bp. (Click link to view GIF of all module methods)
1. Collection of my projects since MS and PhD in Physics from 2014 about Python, SQL, AWS, Azure, PowerBI and Software Developments.
2. If the link does not expand when clicked, please scroll to the bottom of page for full view.
3. I have more than 17000 reputation and more than 5 million page visits in my StackOverflow page, please visit the link for more details.
4. With 10+ years of experience in data science, I have created my own DS library bp. (Click link to view GIF of all module methods)
Chapter: Personal Module For Data Analysis: bp
Personal Module: bp
A01: What does the Module Do? (GIF videos)
API usage
Data Visualization
Data Visualization using Plotly
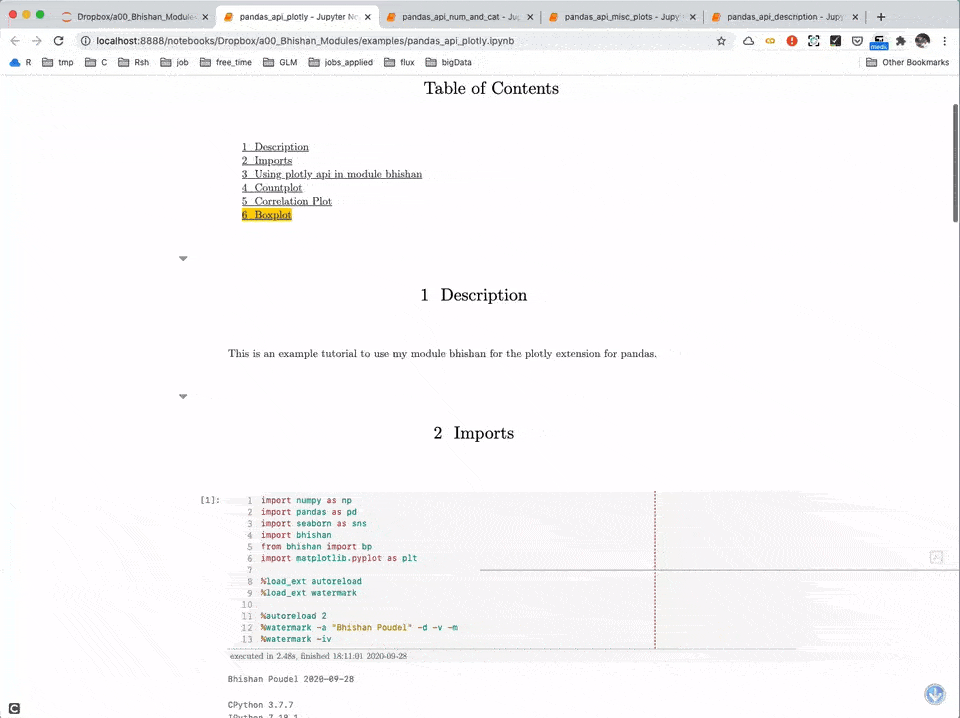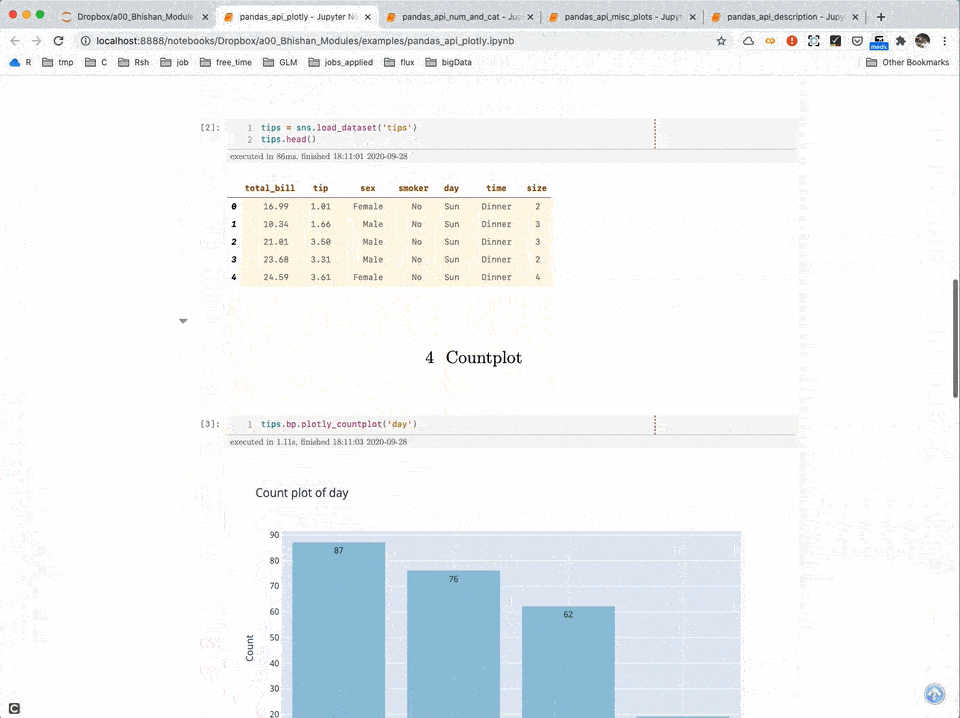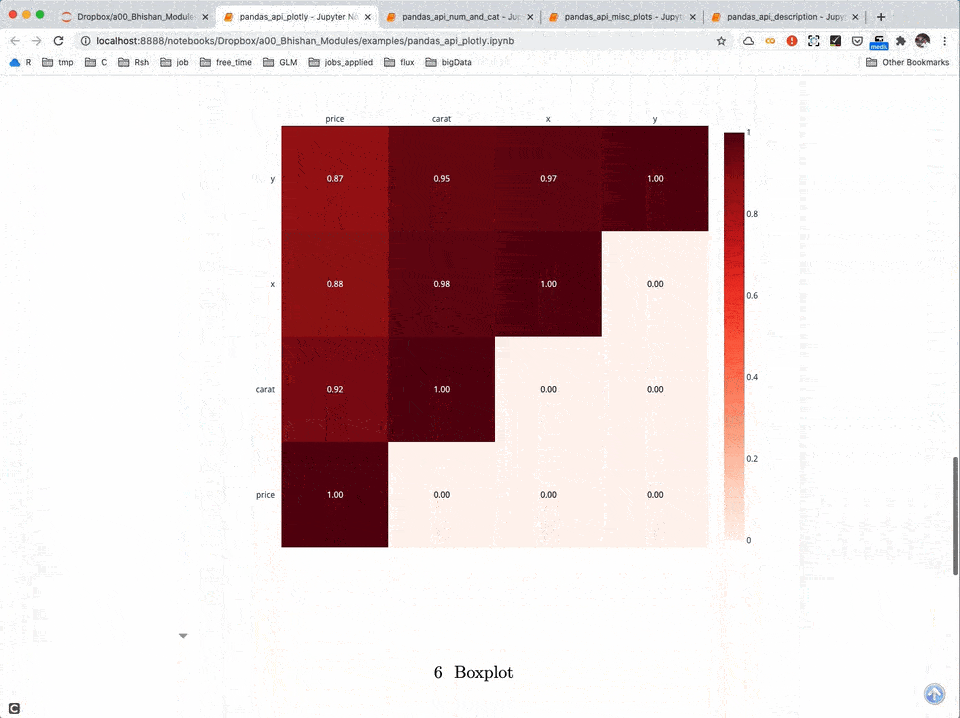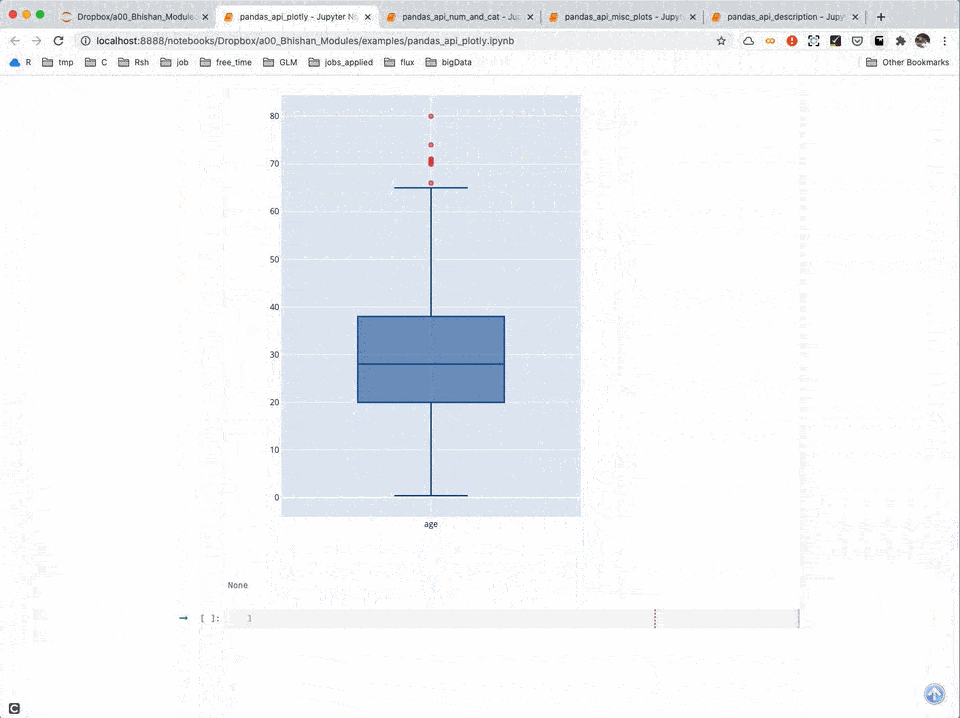
Statistics
Model Evaluation
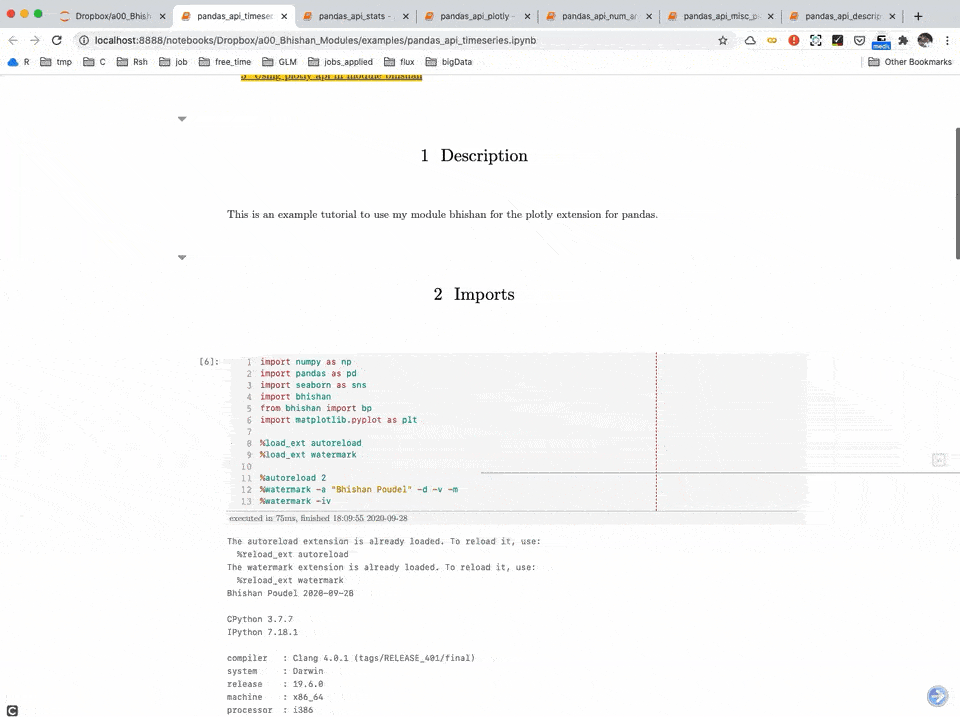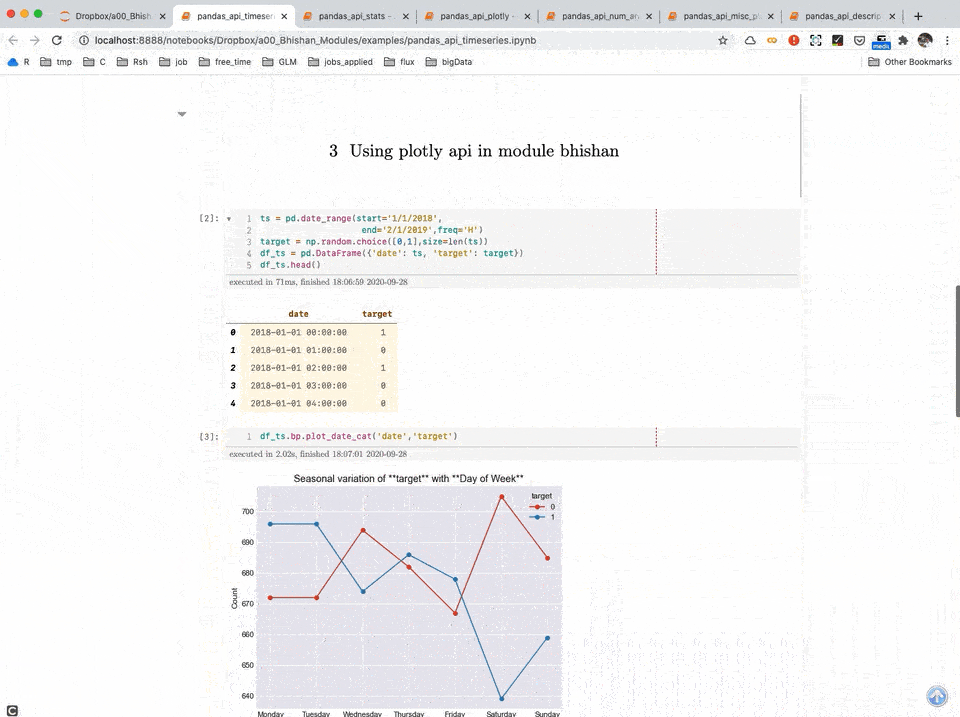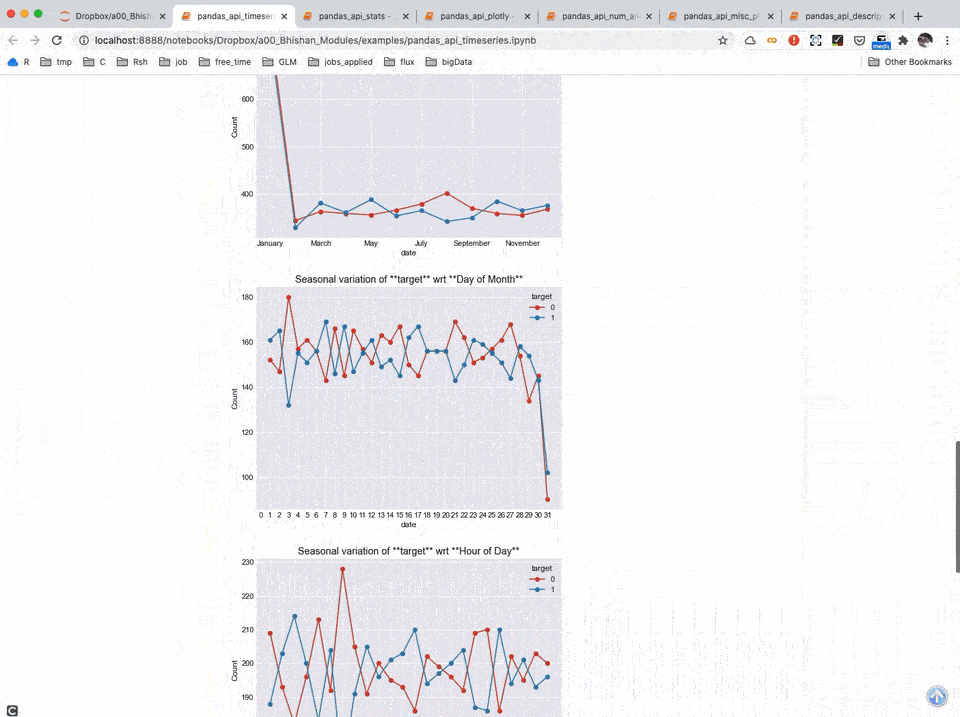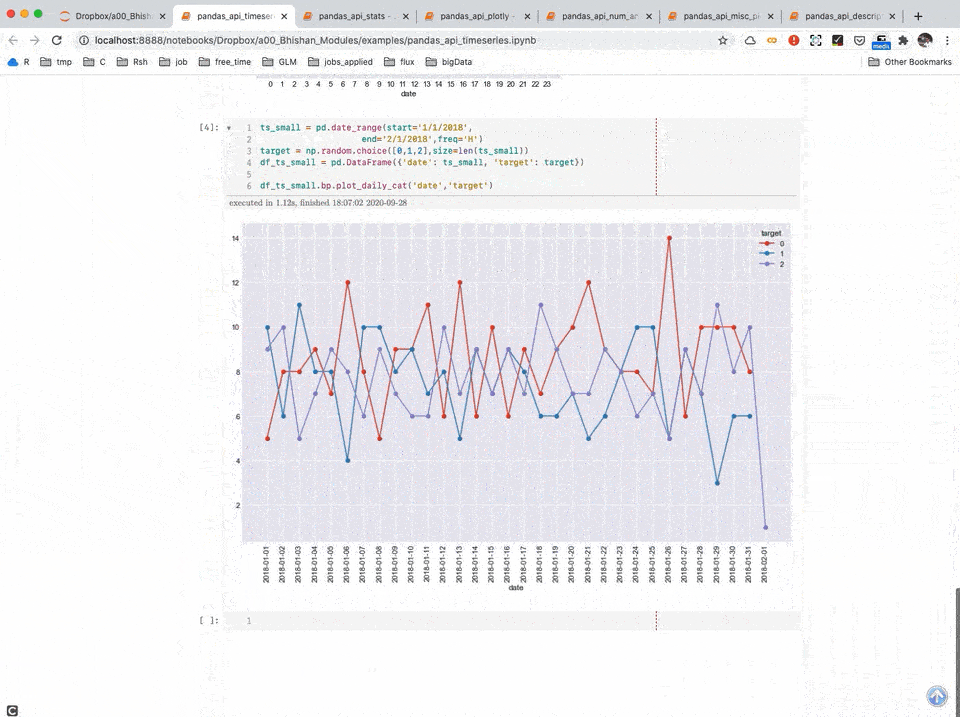
Time Series Analysis
Miscellaneous Usage
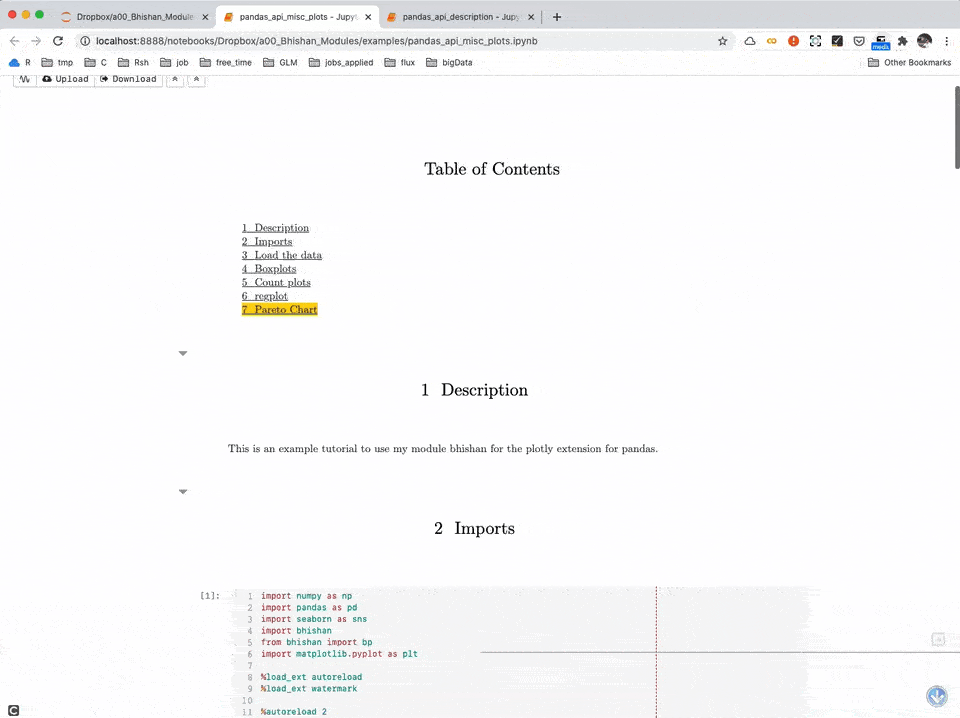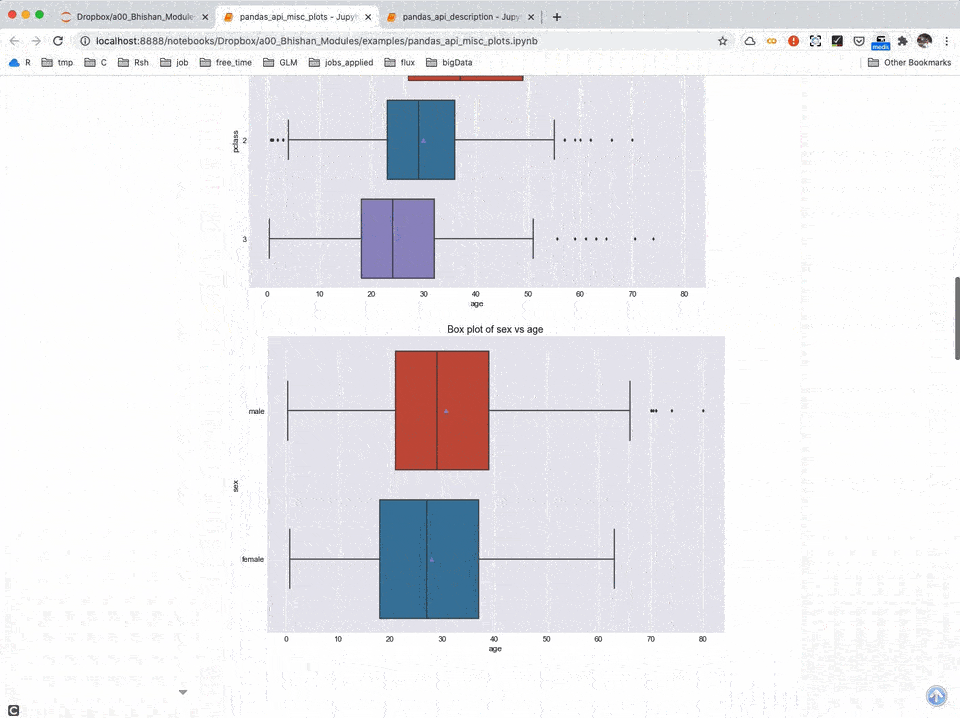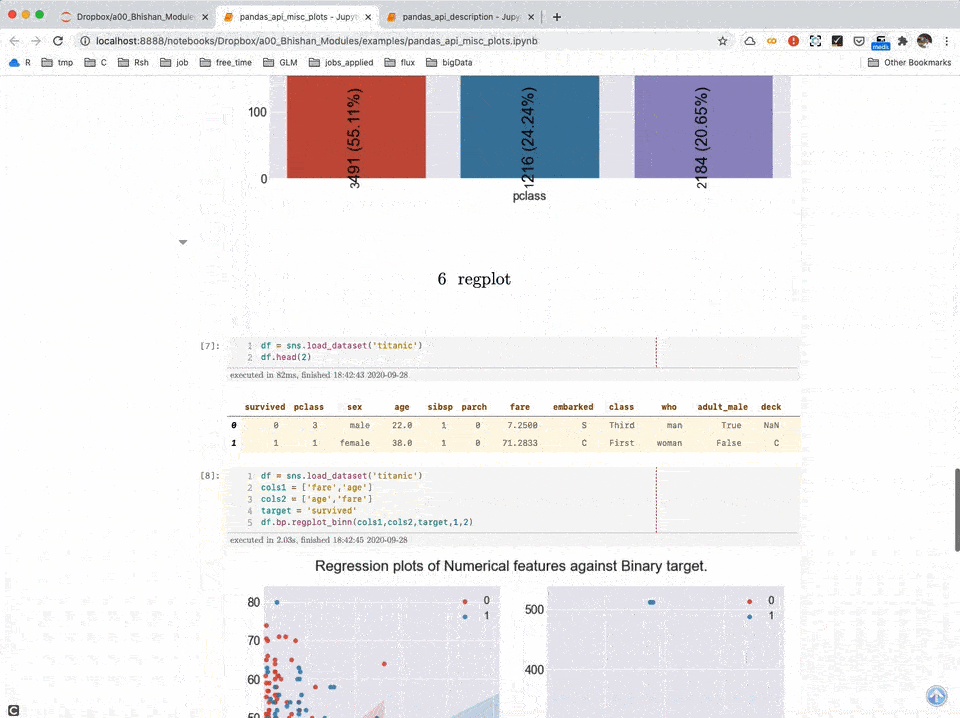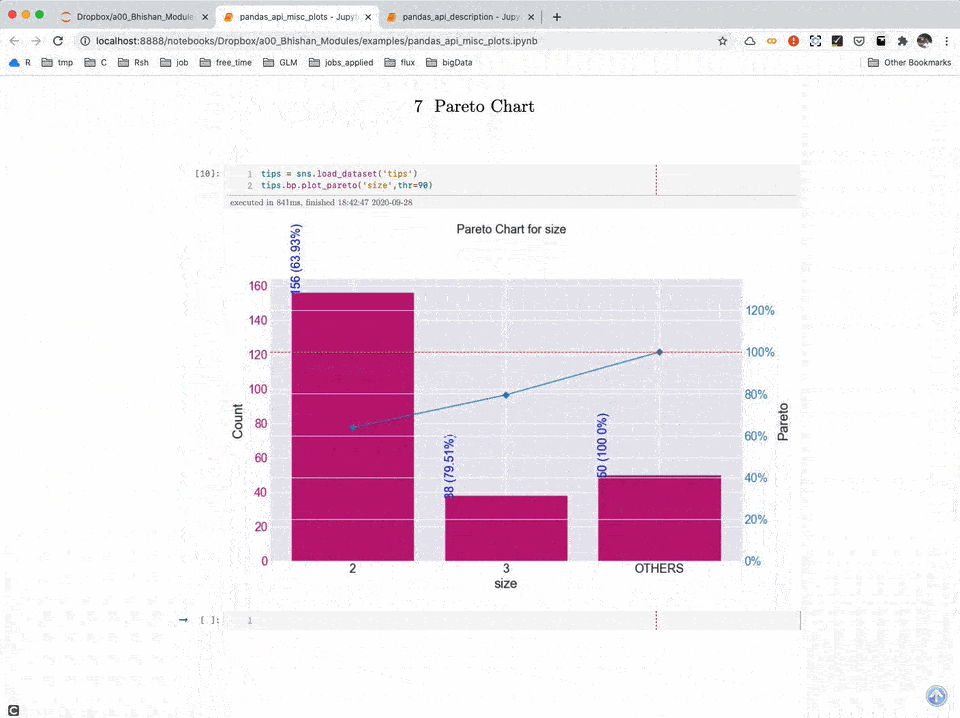
A02: Detailed Use of Module bp (Jupyter Notebooks)
Data Description
Data Visualization
Data Visualization using Plotly
EDA using Plotly
Miscellaneous Plots
Matplotib Styles
Deal with Colors
Statistics
Timeseries Analysis
Model Evaluation
Chapter 1: Data Science Projects
Section A: Regression
A01: King County Seattle House Price Prediction (Regression)
GitHub
README
Statistics Report
a01 Data Processing
a02 Data processing Script
a03 Regression Statistics
a04 Regression EDA
a05 Regression EDA: bokeh
a06 Regression EDA: plotly
a07 Regression EDA: pixiedust
a08 Regression EDA: pandas profiling
b01 Regression Modelling (Boosting): Hist Gradient Boosting
b02 Regression Modelling (Boosting): XGBoost
b03 Regression Modelling (Boosting): LightGBM
b04 Regression Modelling (Boosting): CatBoost
e01 Regression Modelling (Ensemble): Stacking and Blending
m01 Regression Modelling (sklearn): linear and polynomial regression
m02 Regression Modelling (sklearn): sklearn methods
m03 Regression Modelling (sklearn): Random Forest
m04 Regression Modelling (statsmodels): linear OLS
s01 Regression Modelling (Special): pycaret
s02 Feature Engineering (Featuretools): XGBoost
s03 Feature Engineering (Featuretools): LightGBM
s04 Feature Engineering (Featuretools): CatBoost
w01 Model Interpretation: Yellowbrick, Lime, Eli5
w02 Model Interpretation: What If Tool (WIT)
w03 Model Interpretation: Dalex
w04 Model Interpretation: Dtreeviz
x01 Big Data Analysis: PySpark
x02 Big Data Analysis: PySpark Random Forest Tuning
y01 DeepLearning: Keras
z01 Best Model: CatBoost
z02 Best Model: XGBoost
z03 Best Model: Overall
A02: All State Insurance (Insurance: Regression)
GitHub
README
a01 Exploratory Data Analysis
a02 Data Processing
b01 Modelling
b02 Modelling Pyspark
Section B: Classification
BX.01: Fraud Detection (Binary Classification)
GitHub
README
Deploy End to End Machine Learning Model (Fraud Detection) on Heroku
a01 Classification EDA
a02 Classification Statistics
b01a Classification Modelling (Boosting): XGBboost
b01b Classification Modelling (Boosting): XGBboost (HPO)
b01c Classification Modelling (Boosting): XGBboost Custom Loss
b02 Classification Modelling (Boosting): LightGBM
b03 Classification Modelling (Boosting): Catboost
b03b Classification Modelling (Boosting): Catboost Custom Loss
e01 Classification Modelling (Ensemble): Stacking
m01 Classification Modelling (sklearn): Undersampling
m02 Classification Modelling (sklearn): Logistic Regression SMOTE
m03 Classification Modelling (sklearn): Decision Tree
m04 Classification Modelling (sklearn): Calibrated Classification
b05 Classification Modelling (sklearn): Isolation Forest and LOF
s01 Classification Modelling (Special): pycaret (lda)
s02 Classification Modelling (Special): evalML
x01 Classification Modelling (Big Data): dask
x02 Classification Modelling (Big Data): vaex
x03 Classification Modelling (Big Data): pySpark
y01 Classification Modelling (Deep Learning): keras simple model
y02 Classification Modelling (Deep Learning): keras large model
y03 Classification Modelling (Deep Learning): keras oversampling
y04 Classification Modelling (Deep Learning): keras classifier sklearn api
y05 Classification Modelling (Deep Learning): keras classifier (Keras tuner)
BX.02: Customer Churn (Binary Classification)
GitHub
README
a01 Exploratory Data Analysis
a01 Exploratory Data Analysis (Plolty)
a02 Customer Churn: Data Processing
bx01 Modelling (Boosting): XGBoost with HyperbandCV
bx02 Modelling (Boosting): XGBoost with Bayes Optimization
bl01 Modelling (Boosting): LightGBM Classifier with sklearn pipeline and HyperbandCV
bl02 Modelling (Boosting): LightGBM Classifier with Optuna HPO
bl03 Modelling (Boosting): LightGBM Classifier with Hyperopt HPO
bc01 Modelling (Boosting): CatBoostClassifier with optuna hyperparameter tuning
ml01 Modelling (Sklearn): LogisticRegression
ml02 Modelling (Sklearn): LogisticRegressionCV
splr01 Modelling (Special): (Pycaret) Logistic Regression
spn01 Modelling (Special): (Pycaret) Naive Bayes
spx01 Modelling (Special): (Pycaret) Xgboost
spdla01 Modelling (Special): (Pycaret) Linear Discriminant Analysis
sflr01 Modelling (Special): (featuretools) Logistic Regression
se01 Modelling (Special): (evalml) Built-in Algorithm
w01 Model Interpretation: (What If Tool) Logistic Regression
wbl Model Interpretation: (LOFO) Logistic Regression
w01 Model Interpretation: (Interpret) Builtin Estimators Logistic Regression and Boosting
y01 Deep Learning: (Keras) Sequential Simple Model
BX.03: Porto Seguro Auto Insurance (Binary Classification)
GitHub
README
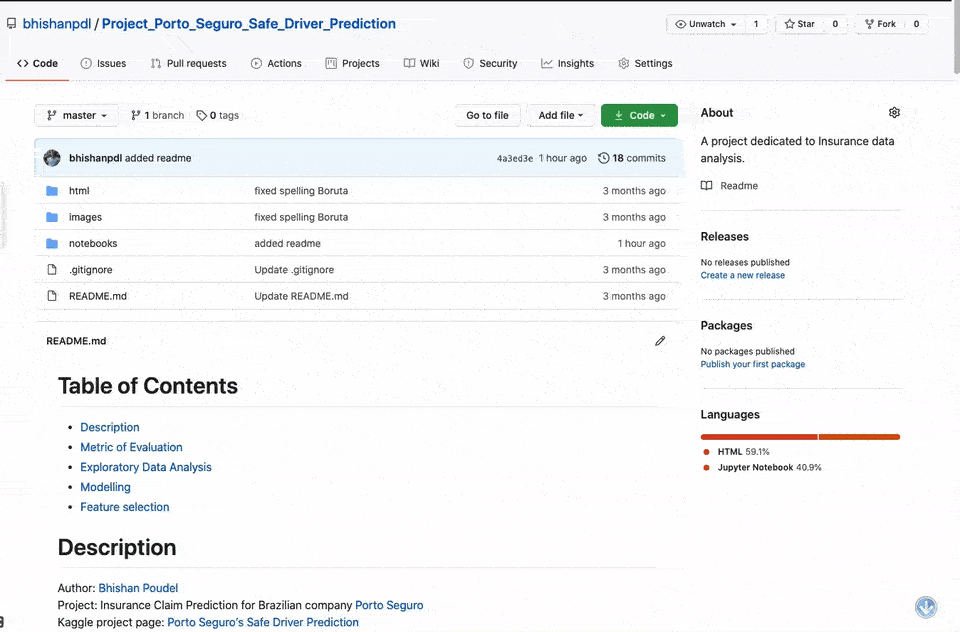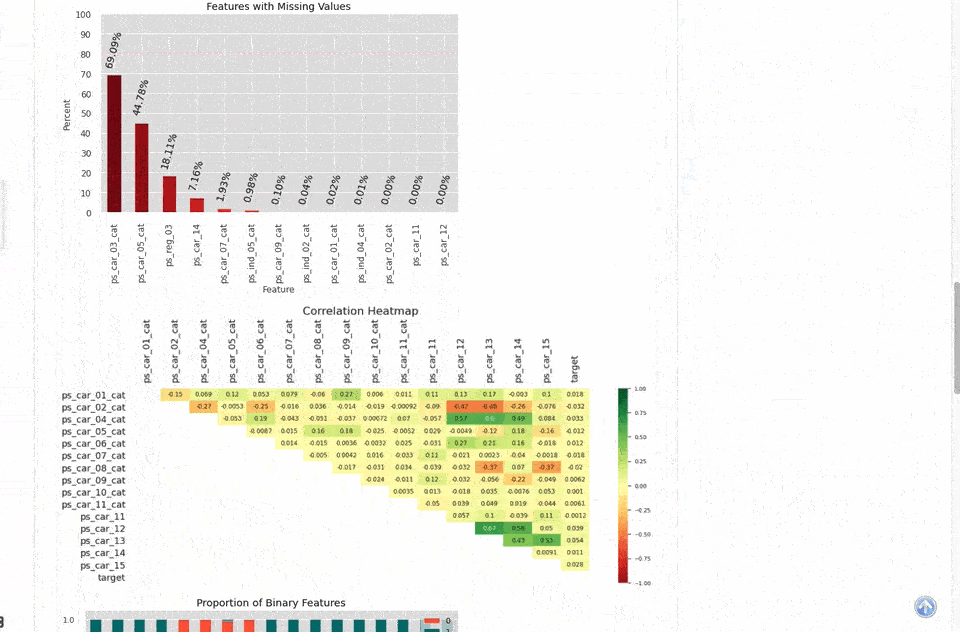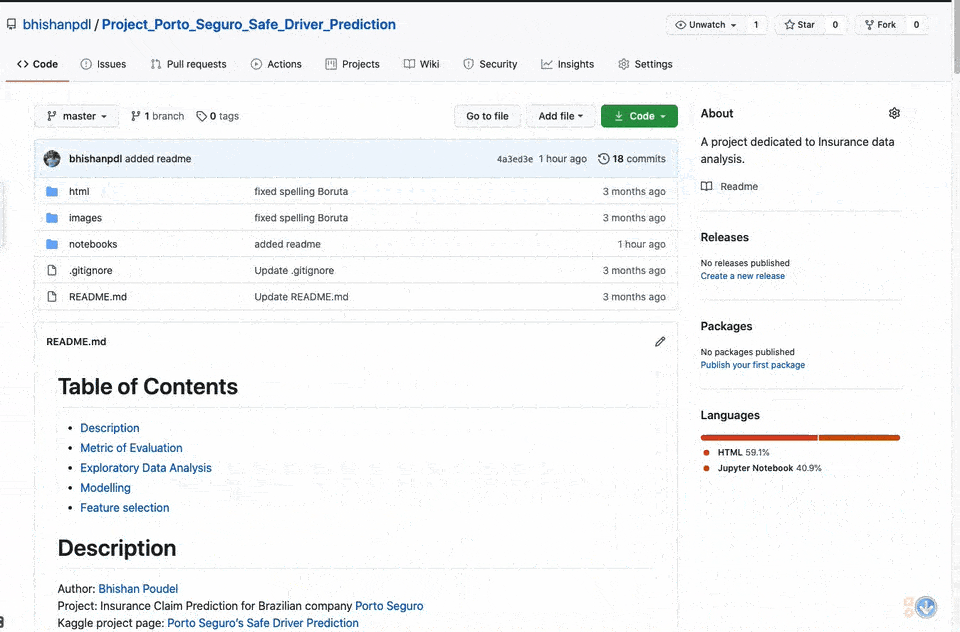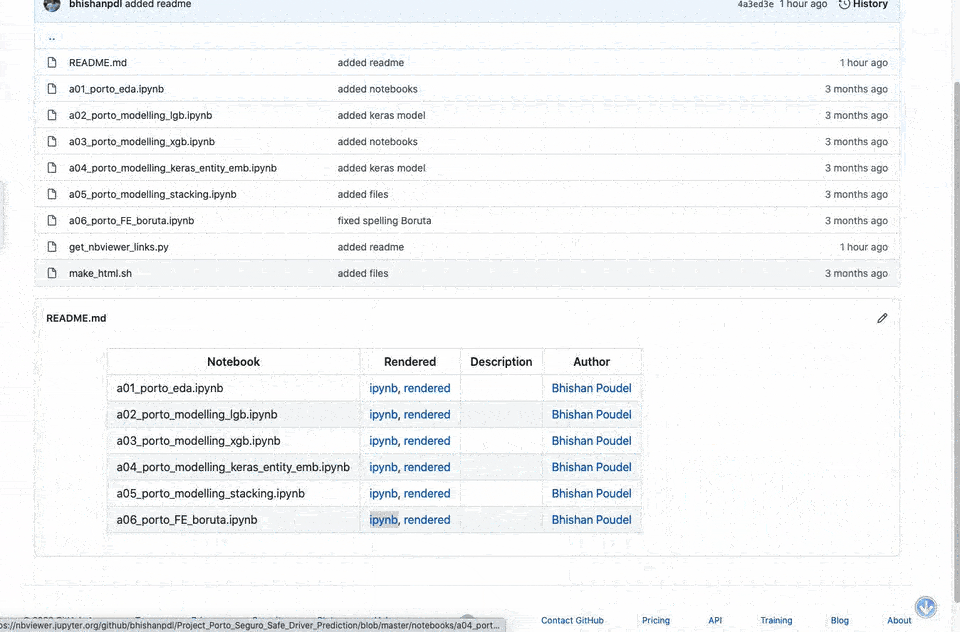
a01 Exploratory Data Analysis
a02 Modelling: LightGBM
a03 Modelling: XGBoost
a04 Modelling: Keras Entity Embedding
a05 Modelling: Stacking different Models
a06 Feature Selection: Boruta and Target Permutation
BX.04: Breast Cancer Wisconsin (Binary Classification)
GitHub
README
a01 Exploratory Data Analysis
b01 Modlling: (Boosting) XGBoost
y01 Deep Learning: Keras Sequential with class_weight
y02 Deep Learning: Keras Sequential
BY.01: Prudential Insurance (Multiclass Classification)
GitHub
README
a01 Exploratory Data Analysis
a02 Multiclass Classification Statistics
a03 Data Preprocessing
a04 Data Preprocessing Script
b01 Modelling: Linear Regression
b02 Modelling: RF Classifier
b03 Modelling: RF Classifier AUC ROC
b04 Modelling: XGBoost Multiclass Classification
b05 Modelling: XGBoost Linear Regression and Poisson Regression with Offset
c01 Multiclass Model Interpretation: eli5, shap and pdpbox
Section C: Clustering
C01: Clinical Features and Biomarkers Analysis for Diabetes (Clustering)
a01 Data Preparation
a02 Statistical Study of Features
b01 Analysis of Clinical Features
b02 Analysis of Biomarkers
m01 Modelling: Diabetes Classification
m02 Modelling: Clustering
s01 Big Data: Modelling Diabetes Data Using Vaex
C02: Clustering Similar Grocery Items (Clustering)
Clustering Grocery Items
C03: Clustering of Agriculture Data (Clustering)
Clustering of Agriculture Data
C04: Clustering of Multiple Sequence Alignment (MSA) of Covid Samples(Clustering)
Clustering of Covid Samples MSA
Section D: Timeseries Analysis
D01: Timeseries Analysis for Web Traffic Data
GitHub
README
a01 Data Processing
b01 Timeseries visualization and eda
c01 Timeseries statistics
d01 Timeseries modelling: ARIMA
d02 Timeseries modelling: VAR
e01 Timeseries modelling: sklearn
f01 Timeseries modelling: tsfresh and xgboost
g01 Timeseries modelling: fbprophet
g02 Timeseries modelling: fbprophet holidays
h01 Timeseries modelling: deep learning
Section E: Natural Language Processing (NLP)
E01: Twitter Sentiment Analysis (Analytics Vidhya Hackathon: Identify the Sentiment)
GitHub
a00 README
a01 Text Data Processing
a02 Text Data EDA
a03 Scattertext for positive and negative sentiments
a03b Result: Twitter Sentiment Html
b01 Text Data Modelling: BoW + Word2Vec + TF-IDF
b02 Text Data Modelling: TF-IDF + Logistic Regression
c01 Sentiment Analysis: ktrain
c01 Sentiment Analysis: ktrain, neptune
c01 Sentiment Analysis: ktrain, neptune HPO
c02 Sentiment Analysis: simpletransformers + Roberta
d01 Sentiment Analysis: (keras) LSTM
d02 Sentiment Analysis: (keras) GRU, CNN, LSTM
e01 Sentiment Analysis: (transformers) Small data with torch and distilbert
e02 Sentiment Analysis: (transformers): Full data with keras and distilbert
e03 Sentiment Analysis: BERT and Tensorflow
e03 Sentiment Analysis: BERT, Tensorflow, and Neptune
E02: Toxic Comments (Multiclass Text Classification)
GitHub
README
a01 Text Data Processing
a02 Text Data EDA
a03 Text Data EDA: Plotly
m01 Text Data Binary Classification (Toxic or not)
s01 Named Entity Recognition and Dependency Parsing: spacy2
s01 Named Entity Recognition and Dependency Parsing: spacy3
y01 Deep Learning: GRU and Fasttext
y01b Deep Learning: GRU, Fasttext, Badwords
y02 Deep Learning: Transformers PyTorch BERT
y02b Deep Learning: Transformers PyTorch XLNET
y02c Deep Learning: Transformers PyTorch DisltilBert
y03 Bert Client: XGBoost
y03b Bert Client: Keras Sequential
E03: Consumer Complaints (Multiclass Text Classification)
GitHub
README
a01 Text Processing
a02 EDA for Text Data
b01 Text Data Modelling: Tf-idf and Sklearn Classifiers
b02 Text Data Modelling: LinearSVC
c01 Model Evaluation: Yellowbrick
c02 Model Evaluation: scikit-plot
d01 Text Data Modelling: PySpark
e01 Text Data Modelling: simpletransformers
Section F: Insurance Data Modelling
F01: French Motor Claims (Pure Premium Modelling)
GitHub
README
a01 Data Cleaning
b01 Frequency Modelling (Poisson Regressor)
b02 Severity Modelling (Gamma Regressor)
b03 Pure Premium Modelling (Tweedie Regressor)
b04 Tweedie Model vs FrequencySeverity Model
b05 Lorentz Curves Comparison
c01 Xgboost with Tweedie Regression
d01 GAM Linearized Modelling using Pygam
Section G: Financial Data Analysis
G01: Credit Risk (Banking: Financial Modelling (Scorecard))
GitHub
README
a01 EDA for Credit Risk Data
a02 Data Processing
b01 Risk Modelling: PDModel Gini KS CreditScore Scorecard
Section H: Recommender System
H01: Books Recommendation System
README
a01 Item Based Recommendation Engine: Cosine Similarity
a02 Item Based Recommendation Engine: Keras
a03 Item Based Recommendation Engine: Torch
b01 Model Based Recommendation Engine: Scipy svds
b02 Model Based Recommendation Engine: Surprise svd
c01 Knowledge Based Recommendation Engine
d01 Content Based Recommender System: TF-IDF
Chapter 2: SQL
2A: SQLITE Queries for Northwind Database (Book: SQL Practice Problems by Vasilik)
a01 Beginner Level Problems (1-19)
a02 Intermediate Level Problems (20-31)
a03 Advanced Level Problems (32-57)
2B.01: SQL Queries for Hospital Management Database
a01 SQL Queries using postgres
a02 SQL Queries using postgres, sqlalachemy and pandas
a03 SQL Queries using sqlite3
2B.02: SQL Queries for Computer Store Database
a01 SQL Queries using postgres
a02 SQL Queries using sqlite
2B.03: SQL Queries for Employee Management Database
a01 SQL Queries using postgres and pyspark
2B.04: SQL Queries for the Warehouse Database
a01 SQL Queries using postgres
a02 SQL Queries using pyspark and postgres
2B.05: SQL Queries for Movie Theaters Database
a01 SQL Queries using pyspark and postgres
a02 SQL Queries using pyspark and sqlite
2B.06: SQL Queries for Pieces and Providers Database
a01 SQL Queries using postgresql
a02 SQL Queries using pyspark, sqlite and sqlalchemy
Chapter 3: Business Projects
3.01: Spanish Translation A/B Testing
GitHub
README
a01 Spanish Translation A/B Testing with Extensive EDA and Statistical Tests
3.02: Customer Lifetime Value
GitHub
README
a01 Data Cleaning
b01 Modelling: BG/NBD and Gamma-Gamma Distribution
b02 Modelling: Keras Modelling and XGBoost
NOTE:
If we are using Safari, we can expand the collapsible links in above section. But for other browsers, such as Google Chrome, the links may not be expanded. In that case, I have included all the expanded version of the links in the below section.
My Personal Module:
bp
If we are using Safari, we can expand the collapsible links in above section. But for other browsers, such as Google Chrome, the links may not be expanded. In that case, I have included all the expanded version of the links in the below section.
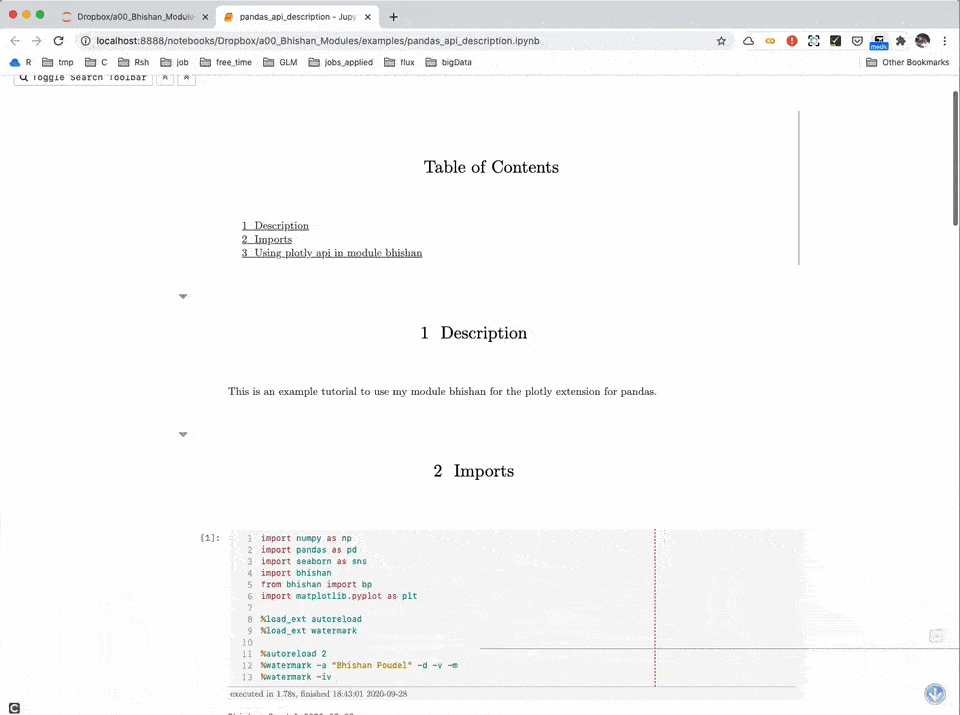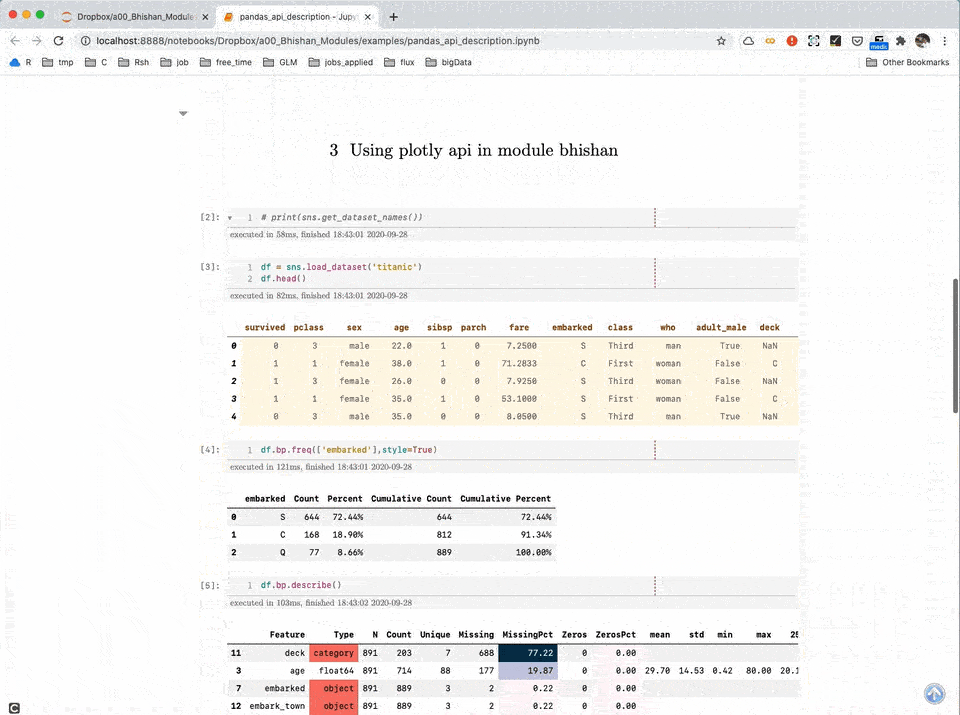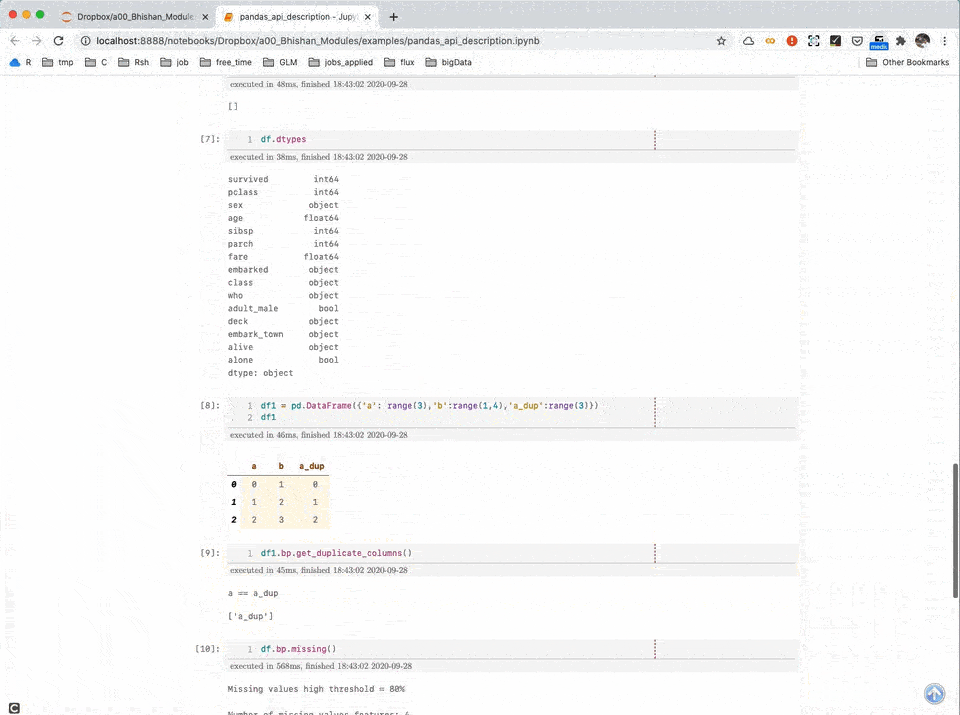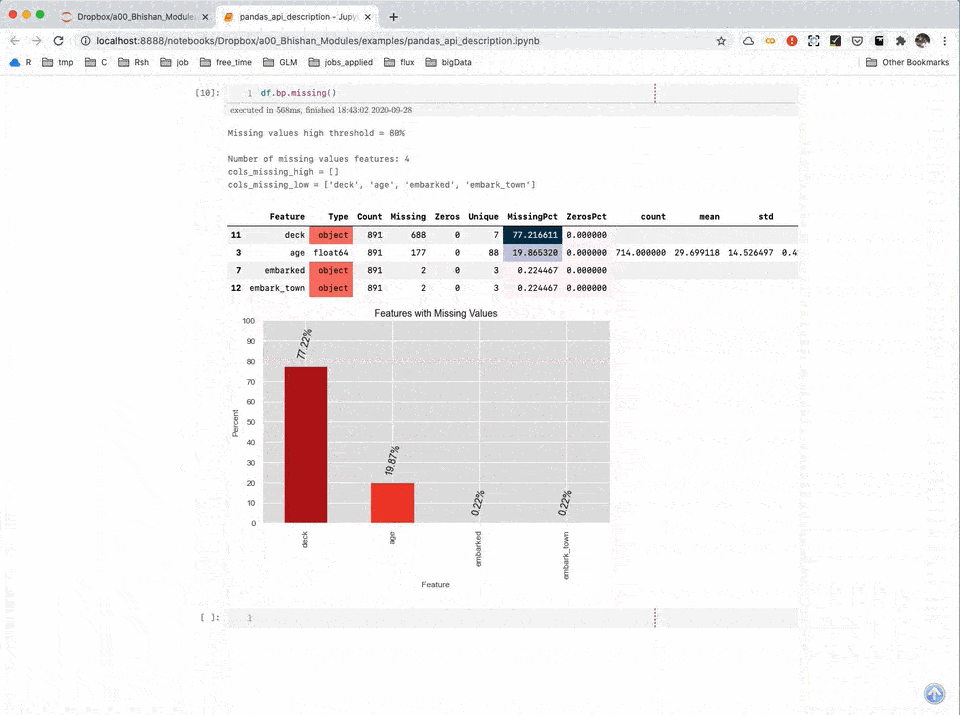
Data Description
Data Visualization
Data Visualization using Plotly
EDA using Plotly
Miscellaneous Plots
Matplotib Styles
Deal with Colors
Statistics
Timeseries Analysis
Model Evaluation
A01: King County Seattle House Price Prediction (Regression)
GitHub
README
Statistics Report
a01 Data Processing
a02 Data processing Script
a03 Regression Statistics
a04 Regression EDA
a05 Regression EDA: bokeh
a06 Regression EDA: plotly
a07 Regression EDA: pixiedust
a08 Regression EDA: pandas profiling
b01 Regression Modelling (Boosting): Hist Gradient Boosting
b02 Regression Modelling (Boosting): XGBoost
b03 Regression Modelling (Boosting): LightGBM
b04 Regression Modelling (Boosting): CatBoost
e01 Regression Modelling (Ensemble): Stacking and Blending
m01 Regression Modelling (sklearn): linear and polynomial regression
m02 Regression Modelling (sklearn): sklearn methods
m03 Regression Modelling (sklearn): Random Forest
m04 Regression Modelling (statsmodels): linear OLS
s01 Regression Modelling (Special): pycaret
s02 Feature Engineering (Featuretools): XGBoost
s03 Feature Engineering (Featuretools): LightGBM
s04 Feature Engineering (Featuretools): CatBoost
w01 Model Interpretation: Yellowbrick, Lime, Eli5
w02 Model Interpretation: What If Tool (WIT)
w03 Model Interpretation: Dalex
w04 Model Interpretation: Dtreeviz
x01 Big Data Analysis: PySpark
x02 Big Data Analysis: PySpark Random Forest Tuning
y01 Deep Learning: Keras
z01 Best Model: CatBoost
z02 Best Model: XGBoost
z03 Best Model: Overall
A02: All State Insurance (Insurance: Regression)GitHub
README
a01 Exploratory Data Analysis
a02 Data Processing
b01 Modelling
b02 Modelling Pyspark
Section B: Classification
BX.01: Fraud Detection (Binary Classification)GitHub
README
Deploy End to End Machine Learning Model (Fraud Detection) on Heroku
a01 Classification EDA
a02 Classification Statistics
b01a Classification Modelling (Boosting): XGBboost
b01b Classification Modelling (Boosting): XGBboost (HPO)
b01c Classification Modelling (Boosting): XGBboost
b02 Classification Modelling (Boosting): LightGBM
b03 Classification Modelling (Boosting): Catboost
b03b Classification Modelling (Boosting): Catboost Custom Loss
e01 Classification Modelling (Ensemble): Stacking
m01 Classification Modelling (sklearn): Undersampling
m02 Classification Modelling (sklearn): Logistic Regression SMOTE
m03 Classification Modelling (sklearn): Decision Tree
m04 Classification Modelling (sklearn): Calibrated Classification
b05 Classification Modelling (sklearn): Isolation Forest and LOF
s01 Classification Modelling (Special): pycaret (lda)
s02 Classification Modelling (Special): evalML
x01 Classification Modelling (Big Data): dask
x02 Classification Modelling (Big Data): vaex
x03 Classification Modelling (Big Data): pySpark
y01 Classification Modelling (Deep Learning): keras simple model
y02 Classification Modelling (Deep Learning): keras large model
y03 Classification Modelling (Deep Learning): keras oversampling
y04 Classification Modelling (Deep Learning): keras classifier sklearn api
y05 Classification Modelling (Deep Learning): keras classifier (Hyperparameter tuning)
BX.02: Customer Churn (Binary Classification)GitHub
README
a01 Exploratory Data Analysis
a01 Exploratory Data Analysis (Plolty)
a02 Customer Churn: Data Processing
bx01 Modelling (Boosting): XGBoost with HyperbandCV
bx02 Modelling (Boosting): XGBoost with Bayes Optimization
bl01 Modelling (Boosting): LightGBM Classifier with sklearn pipeline and HyperbandCV
bl02 Modelling (Boosting): LightGBM Classifier with Optuna HPO
bl03 Modelling (Boosting): LightGBM Classifier with Hyperopt HPO
bc01 Modelling (Boosting): CatBoostClassifier with optuna hyperparameter tuning
ml01 Modelling (Sklearn): LogisticRegression
ml02 Modelling (Sklearn): LogisticRegressionCV
splr01 Modelling (Special): (Pycaret) Logistic Regression
spn01 Modelling (Special): (Pycaret) Naive Bayes
spx01 Modelling (Special): (Pycaret) Xgboost
spdla01 Modelling (Special): (Pycaret) Linear Discriminant Analysis
sflr01 Modelling (Special): (featuretools) Logistic Regression
se01 Modelling (Special): (evalml) Built-in Algorithm
w01 Model Interpretation: (What If Tool) Logistic Regression
wbl Model Interpretation: (LOFO) Logistic Regression
w01 Model Interpretation: (Interpret) Builtin Estimators Logistic Regression and Boosting
y01 Deep Learning: (Keras) Sequential Simple Model
BX.03: Porto Seguro Auto Insurance (Binary Classification)GitHub
README
a01 Exploratory Data Analysis
a02 Modelling: LightGBM
a03 Modelling: XGBoost
a04 Modelling: Keras Entity Embedding
a05 Modelling: Stacking different Models
a06 Feature Selection: Boruta and Target Permutation
BX.04: Breast Cancer Wisconsin (Binary Classification)GitHub
README
a01 Exploratory Data Analysis
b01 Modlling: (Boosting) XGBoost
y01 Deep Learning: Keras Sequential with class_weight
y02 Deep Learning: Keras Sequential
BY.01: Prudential Insurance (Multiclass Classification)GitHub
README
a01 Exploratory Data Analysis
a02 Multiclass Classification Statistics
a03 Data Preprocessing
a04 Data Preprocessing Script
b01 Modelling: Linear Regression
b02 Modelling: RF Classifier
b03 Modelling: RF Classifier AUC ROC
b04 Modelling: XGBoost Multiclass Classification
b05 Modelling: XGBoost Linear Regression and Poisson Regression with Offset
c01 Multiclass Model Interpretation: eli5, shap and pdpbox
Section C: Clustering
C01: Clinical Features and Biomarkers Analysis for Diabetes (Clustering)a01 Data Preparation
a02 Statistical Study of Features
b01 Analysis of Clinical Features
b02 Analysis of Biomarkers
m01 Modelling: Diabetes Classification
m02 Modelling: Clustering
s01 Big Data: Modelling Diabetes Data Using Vaex
C02: Clustering of Grocery Items (Clustering)
Clustering of Grocery Items
C03: Clustering of Agriculture Data (Clustering)
Clustering of Agriculture Data
C04: Clustering Covid Samples Multiple Sequence Alignment (Clustering)
Clustering Covid Samples Multiple Sequence Alignment
Section D: Timeseries Analysis
D01: Timeseries Analysis for Web Traffic DataGitHub
README
a01 Data Processing
b01 Timeseries visualization and eda
c01 Timeseries statistics
d01 Timeseries modelling: ARIMA
d02 Timeseries modelling: VAR
e01 Timeseries modelling: sklearn
f01 Timeseries modelling: tsfresh and xgboost
g01 Timeseries modelling: fbprophet
g02 Timeseries modelling: fbprophet holidays
h01 Timeseries modelling: deep learning
Section E: Natural Language Processing (NLP)
E01: Twitter Sentiment Analysis (Analytics Vidhya Hackathon: Identify the Sentiment)GitHub
a00 README
a01 Text Data Processing
a02 Text Data EDA
a03 Scattertext for positive and negative sentiments
a03b Result: Twitter Sentiment Html
b01 Text Data Modelling: BoW + Word2Vec + TF-IDF
b02 Text Data Modelling: TF-IDF + Logistic Regression
c01 Sentiment Analysis: ktrain
c01 Sentiment Analysis: ktrain, neptune
c01 Sentiment Analysis: ktrain, neptune HPO
c02 Sentiment Analysis: simpletransformers + Roberta
d01 Sentiment Analysis: (keras) LSTM
d02 Sentiment Analysis: (keras) GRU, CNN, LSTM
e01 Sentiment Analysis: (transformers) Small data with torch and distilbert
e02 Sentiment Analysis: (transformers): Full data with keras and distilbert
e03 Sentiment Analysis: BERT and Tensorflow
e03 Sentiment Analysis: BERT, Tensorflow, and Neptune
E02: Toxic Comments (Multiclass Text Classification)GitHub
README
a01 Text Data Processing
a02 Text Data EDA
a03 Text Data EDA: Plotly
m01 Text Data Binary Classification (Toxic or not)
s01 Named Entity Recognition and Dependency Parsing: spacy2
s01 Named Entity Recognition and Dependency Parsing: spacy3
y01 Deep Learning: GRU and Fasttext
y01b Deep Learning: GRU, Fasttext, Badwords
y02 Deep Learning: Transformers PyTorch BERT
y02b Deep Learning: Transformers PyTorch XLNET
y02c Deep Learning: Transformers PyTorch DisltilBert
y03 Bert Client: XGBoost
y03b Bert Client: Keras Sequential
E03: Consumer Complaints (Multiclass Text Classification)GitHub
README
a01 Text Processing
a02 EDA for Text Data
b01 Text Data Modelling: Tf-idf and Sklearn Classifiers
b02 Text Data Modelling: LinearSVC
c01 Model Evaluation: Yellowbrick
c02 Model Evaluation: scikit-plot
d01 Text Data Modelling: PySpark
e01 Text Data Modelling: simpletransformers
Section F: Insurance Data Modelling
F01: French Motor Claims (Pure Premium Modelling)GitHub
README
a01 Data Cleaning
b01 Frequency Modelling (Poisson Regressor)
b02 Severity Modelling (Gamma Regressor)
b03 Pure Premium Modelling (Tweedie Regressor)
b04 Tweedie Model vs FrequencySeverity Model
b05 Lorentz Curves Comparison
c01 Xgboost with Tweedie Regression
d01 GAM Linearized Modelling using Pygam
Section G: Financial Data Analysis
G01: Credit Risk (Banking: Financial Modelling (Scorecard))GitHub
README
a01 EDA for Credit Risk Data
a02 Data Processing
b01 Risk Modelling: PDModel Gini KS CreditScore Scorecard
Section H: Recommender System
H01: Books Recommendation SystemREADME
a01 Item Based Recommendation Engine: Cosine Similarity
a02 Item Based Recommendation Engine: Keras
a03 Item Based Recommendation Engine: Torch
b01 Model Based Recommendation Engine: Scipy svds
b02 Model Based Recommendation Engine: Surprise svd
c01 Knowledge Based Recommendation Engine
d01 Content Based Recommender System: TF-IDF
Chapter 2: SQL
2A: SQLITE Queries for Northwind Database (Book: SQL Practice Problems by Vasilik)a01 Beginner Level Problems (1-19)
a02 Intermediate Level Problems (20-31)
a03 Advanced Level Problems (32-57)
2B.01: SQL Queries for Hospital Management Databasea01 SQL Queries using postgres
a02 SQL Queries using postgres, sqlalachemy and pandas
a03 SQL Queries using sqlite3
2B.02: SQL Queries for Computer Store Databasea01 SQL Queries using postgres
a02 SQL Queries using sqlite
2B.03: SQL Queries for Employee Management Databasea01 SQL Queries using postgres and pyspark
2B.04: SQL Queries for the Warehouse Databasea01 SQL Queries using postgres
a02 SQL Queries using pyspark and postgres
2B.05: SQL Queries for Movie Theaters Databasea01 SQL Queries using pyspark and postgres
a02 SQL Queries using pyspark and sqlite
2B.06: SQL Queries for Pieces and Providers Databasea01 SQL Queries using postgresql
a02 SQL Queries using pyspark, sqlite and sqlalchemy
Chapter 3: Business Projects
3.01: Spanish Translation A/B TestingGitHub
README
a01 Spanish Translation A/B Testing with Extensive EDA and Statistical Tests
3.02: Customer Lifetime ValueGitHub
README
a01 Data Cleaning
b01 Modelling: BG/NBD and Gamma-Gamma Distribution
b02 Modelling: Keras Sequential and XGBoost
Chapter 4: Personal Module "bp"
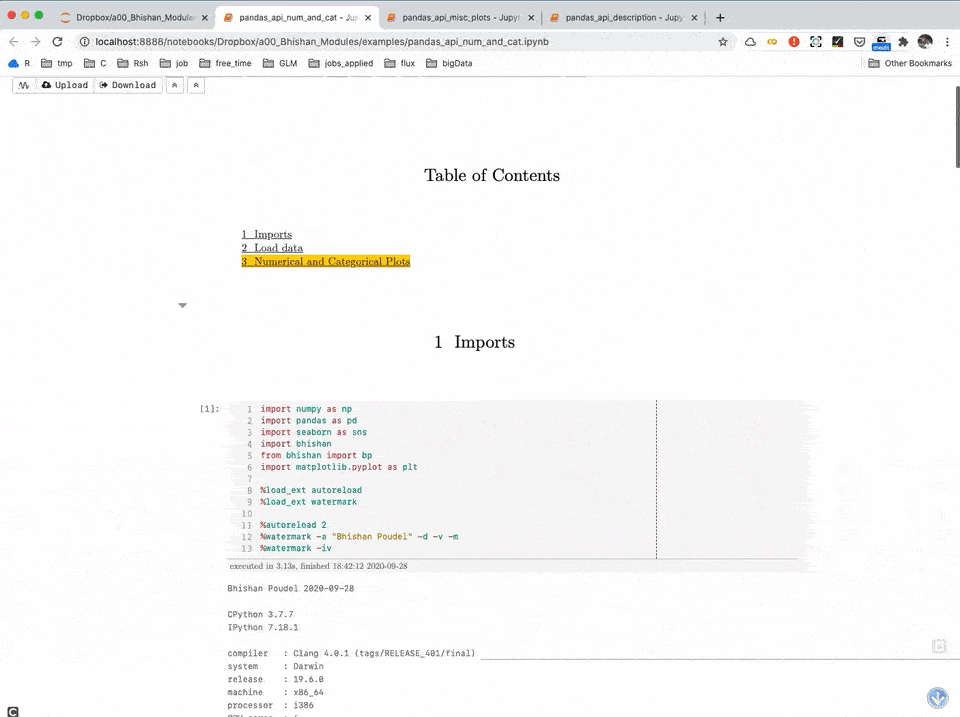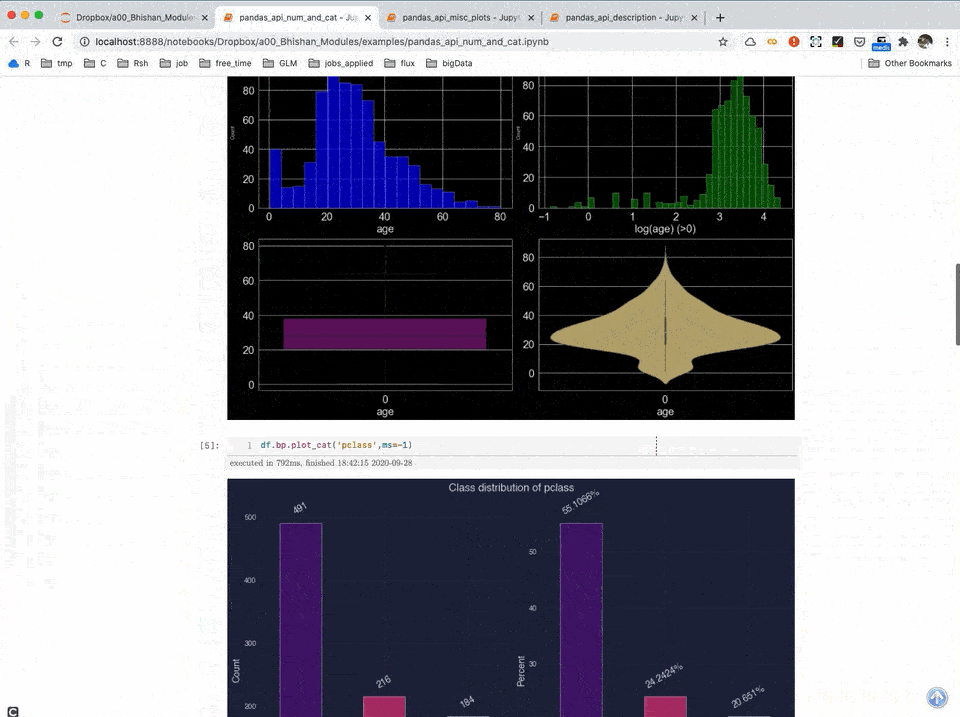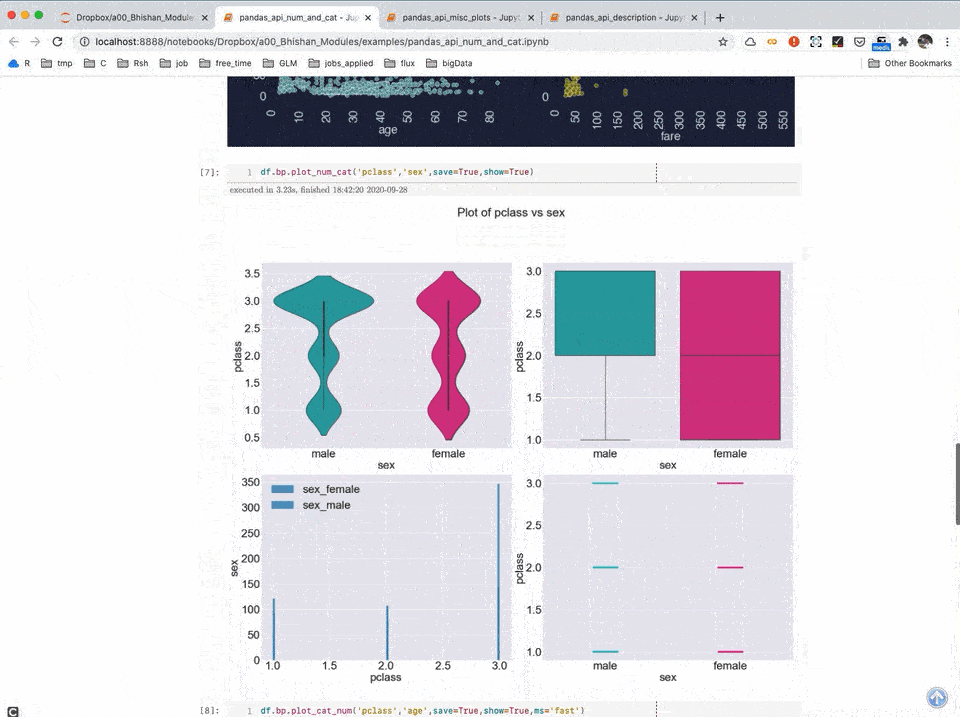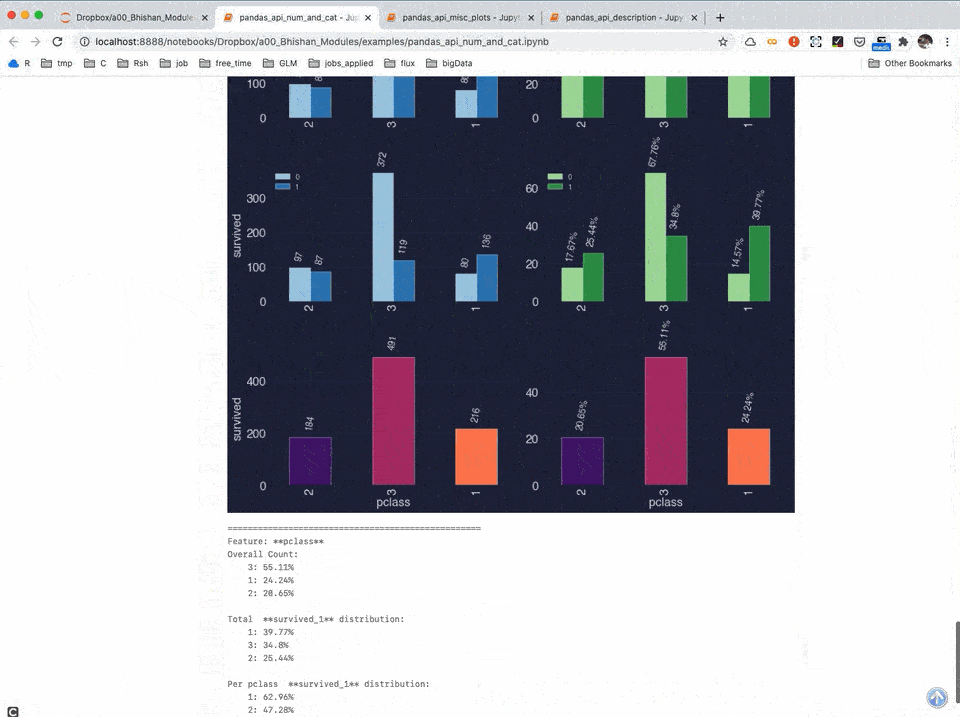
The module "bp" expands pandas DataFrame API and adds various visualization and data analysis functionalities. For example, we can get a plot of a numeric column using the method "df.bp.plot_num("my_numeric_variable")".
Currently my module contains following methods:
| 1 | 2 | 3 | 4 | |||
|---|---|---|---|---|---|---|
| BPAccessor | hlp | plot_daily_cat | plotly_corr_heatmap | |||
| Plotly_Charts | json | plot_date_cat | plotly_countplot | |||
| RandomColor | light_axis | plot_ecdf | plotly_country_plot | |||
| add_interactions | lm_plot | plot_gini | plotly_distplot | |||
| add_text_barplot | lm_residual_corr_plot | plot_ks | plotly_histogram | |||
| adjustedR2 | lm_stats | plot_multiple_jointplots_with_pearsonr | plotly_mapbox | |||
| hex_to_rgb | magnify | plot_num | plotly_radar_plot | |||
| discrete_cmap | multiple_linear_regression | plot_num_cat | plotly_scattergl_plot | |||
| display_calendar | no_axis | plot_num_cat2 | plotly_scattergl_plot_colorcol | |||
| plot_plot_binn | optimize_memory | plot_num_num | plotly_scattergl_plot_subplots | |||
| find_corr | parallelize_dataframe | plot_pareto | plotly_usa_bubble_map | |||
| freq_count | parse_json_col | plot_roc_auc | plotly_usa_map | |||
| get_binary_classification_report | partial_corr | plot_roc_skf | plotly_usa_map2 | |||
| get_binary_classification_scalar_metrics | plot_boxplot_cats_num | plot_simple_linear_regression | point_biserial_correlation | |||
| get_binary_classification_scalar_metrics2 | plot_cat | plot_statistics | print_calendar | |||
| get_column_descriptions | plot_cat_binn | plot_stem | print_confusion_matrix | |||
| get_distinct_colors | plot_cat_cat | plot_two_clusters | print_df_eval | |||
| get_false_negative_frauds | plot_cat_cat2 | plotly_agg_country_plot | print_statsmodels_summary | |||
| get_high_correlated_features_df | plot_cat_cat_pct | plotly_agg_usa_plot | random | |||
| get_mpl_style | plot_cat_num | plotly_binary_clf_evaluation | regression_residual_plots | |||
| get_outliers | plot_confusion_matrix_plotly | plotly_boxplot | remove_outliers | |||
| get_outliers_kde | plot_corr | plotly_boxplot_allpoints_with_outliers | rgb2hex | |||
| get_plotly_colorscale | plot_corr_style | plotly_boxplot_categorical_column | select_kbest_features | |||
| get_yprobs_sorted_proportions | plot_corrplot_with_pearsonr | plotly_bubbleplot | show_methods |
Chapter 5: Overview of My Projects (GIF Videos)
- Click on the box to show the GIF video. (The box moves down and GIF video plays above it.)
- Go to the buttom of the gif and click the same button again to hide the video.